
2026-01-03
 Vibecoding 时代,程序员会消失吗?——从“全自动”到“半自动”的冷思考
Vibecoding 时代,程序员会消失吗?——从“全自动”到“半自动”的冷思考
今年,“Vibecoding” 的概念席卷了技术圈。像 ClaudeCode、Lovable 这类产品,号称只需一句自然语言就能生成整套应用;CodingAgent 更是通过不断的 Action-Observation 循环,模仿人类一步步
2025-12-18
 AzureOpenAI vs OpenAI
AzureOpenAI vs OpenAI
OpenAI是一家人工智能研究机构,最近几个月发布的ChatGPT火遍全球。OpenAI官方提供了API接口,可以帮助开发者轻松地介入Ada、Babbage、Curie、Davinci等模型,尤其是OpenAI发布的text-davinci
2023-02-17
 ChatGPT出圈的秘诀
ChatGPT出圈的秘诀
通篇翻译自Rajani et al., “What Makes a Dialog Agent Useful?”, Hugging Face Blog, 2023.
ChatGPT背后的技术:RLHF、IFT、CoT、Red teaming
2023-01-29
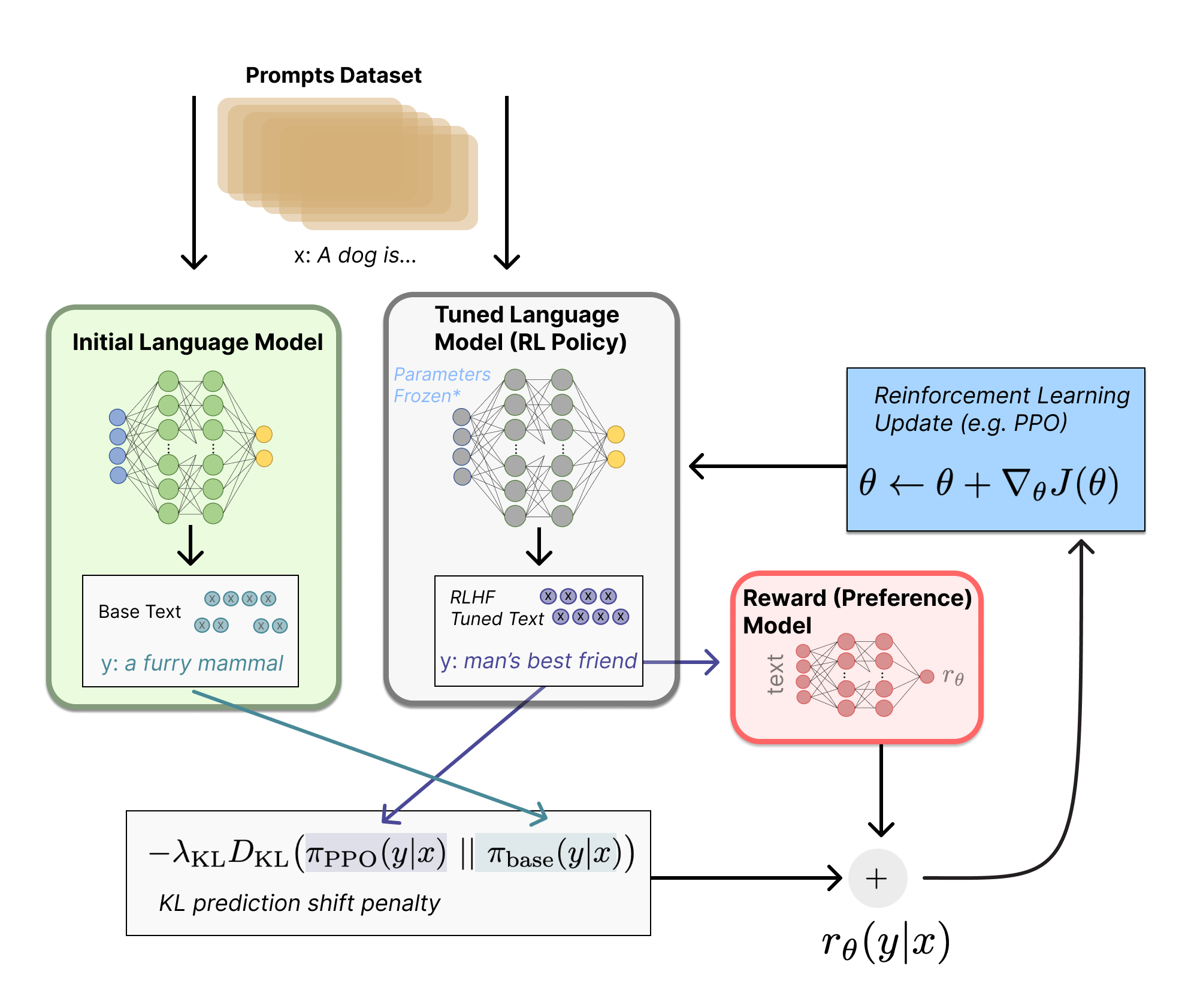 人工反馈的强化学习
人工反馈的强化学习
人工反馈的强化学习
翻译自Huggingface博客
近几年,通过人工prompt提示,语言模型可以出色的生成多样的或限定的文本。但是,如何界定“好”的生成文本是很难的,因为它很主观,同时需要考虑上下文的。例如有很多应用,比如写故事,是希
2023-01-02
 Stable Diffusion的模型量化,降低内存75%、Streamlit的在线生成图片调试、docker服务部署
Stable Diffusion的模型量化,降低内存75%、Streamlit的在线生成图片调试、docker服务部署
摘要最近几个月开源的Stable Diffusion模型是一个非常棒的模型,它在图像生成领域有着现象级的表现。网上已经有分享大量关于它的画质精美的生成图像。但这个模型是有着10亿级别的参数量,5.2GB的内存占用,一般的家用显卡很难运行起来
2022-10-09
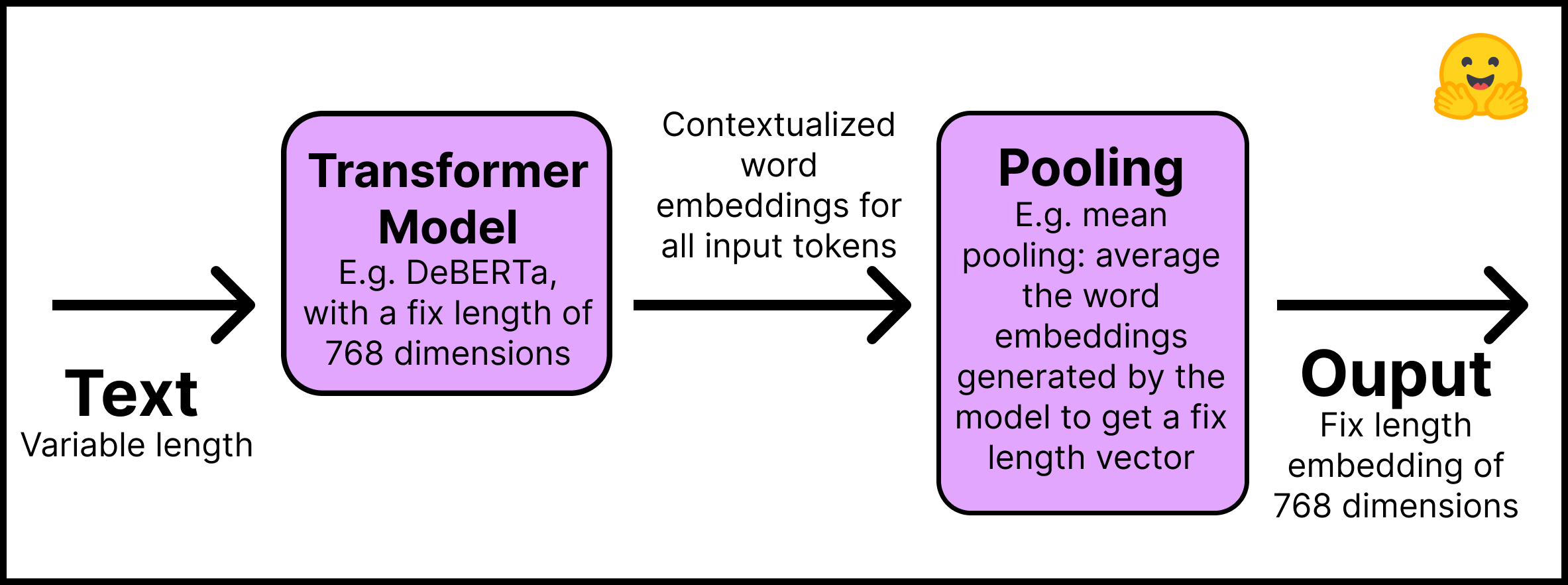 训练一个SentenceTransformer模型
训练一个SentenceTransformer模型
原博客完整notebook代码
训练或是微调SentenceTransformer模型,主要取决于有什么样的数据,做什么样的任务。
输入模型的数据如何处理
不同损失函数与数据集的关系
在这篇博客里,我们可以:
学会如何从零创建一个
2022-09-12
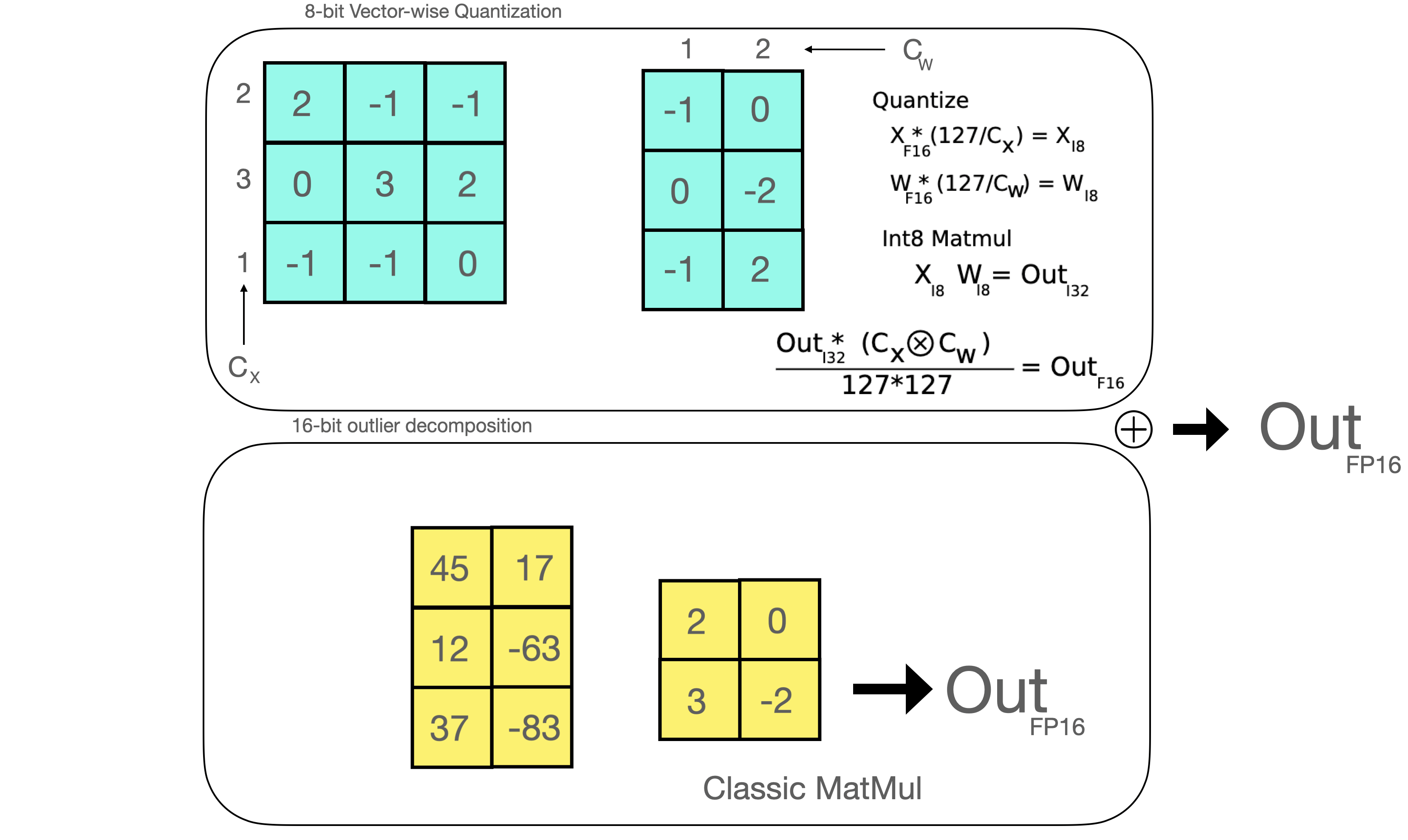 8位混合精度矩阵乘法,小硬件跑大模型
8位混合精度矩阵乘法,小硬件跑大模型
原论文:https://arxiv.org/pdf/2208.07339.pdf
原博客:https://huggingface.co/blog/hf-bitsandbytes-integration
背景NLP语言模型一直在变大,如今
2022-09-04
 Constrained Beam Search
Constrained Beam Search
使用Transformers做限制集束搜索(Constrained Beam Search)的文本生成
翻译自Guiding Text Generation with Constrained Beam Search in 🤗 Transf
2022-07-03
 盘点开源“Copilot”,do it yourself
盘点开源“Copilot”,do it yourself
目录
盘点开源“Copilot”,do it by yourself
目录
1.背景
2.简述
3. 盘点开源代码生成模型
3.1. 模型清单
3.2. 模型测试
3.2.1. Python语言代码生成测试1
3.2.2. Python语言
2022-06-27
 使用fastgpt提速huggingface的GPT文本生成模型
使用fastgpt提速huggingface的GPT文本生成模型
使用fastgpt提速huggingface的GPT文本生成模型
fastgpt 是什么
fastgpt是一个基于transformers和onnxruntime的python库,可以无缝衔接的使用 onnxruntime 量化后的 tra
2022-06-25
 docker启devpi服务
docker启devpi服务
相关链接:
github
dockerhub简要
devpi工具相比其他pypi源工具,有如下特点:
节省硬盘:不必完全同步下来公开源的所有包,仅在第一次pip安装时从公开源下载和缓存。
支持上传接口文档:上传自己开发pip库时,可以把接口
2022-03-05