- 本博客翻译自huggingface blog
简介
最近几年,以OpenAI公司的GPT3为代表,基于transformer结构的大模型都已经开始在上百万级别的网页上面训练。因此大家对开放领域语言生成的期待值也越来越高。开放领域的条件语言生成效果也日新月异,例如GPT2、XLNet、CTRL。除了transformers结构和海量的无监督预训练数据,更好的解码方法也在其中扮演了重要角色。
这篇博客简要回顾了多种解码策略,帮助你用transformers库实现他们。
所有的方法都可以通过自回归(auto-regressive)语言生成实现新手导航,简而言之,自回归语言生成就是基于当前的词分布,预测下一个词的概率分布。
$$P(w_{1:T}|W_0) = \prod_{t=1}^TP(w_t|w_{1:t-1},W_0), with\ w_{1:0}=\emptyset$$
这里$W_0$表示生成前的初始词序列,生成词序列的长度$T$取决于生成概率中$P(w_t|w_{1:t-1},W_0)$何时生成词$EOS$。
自回归语言生成模型,例如GPT2、XLNet、OpenAi-GPT、CTRL、TransfoXL、XLM、Bart、T5,如今在PyTorch、Tensorflow>=2.0框架下,都可以运行 !
下面我们会过一下当前最主要的解码方法:Greedy search、Beam search、Top-K sampling、Top-p sampling。
首先我们来安装transformers以及加载模型。我们用Tensorflow 2.1的GPT2为例,但接口和Pytorch是一样的。
pip install -q git+https://github.com/huggingface/transformers.git
pip install -q tensorflow==2.1import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = TFGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)Greedy Search
Greedy search是指在每个$t$时刻选择下一个词时,根据$w_t=argmax_wP(w|w_{1:t-1})$选择概率最高的词。下面这张图给出Greedy search的解码路径。
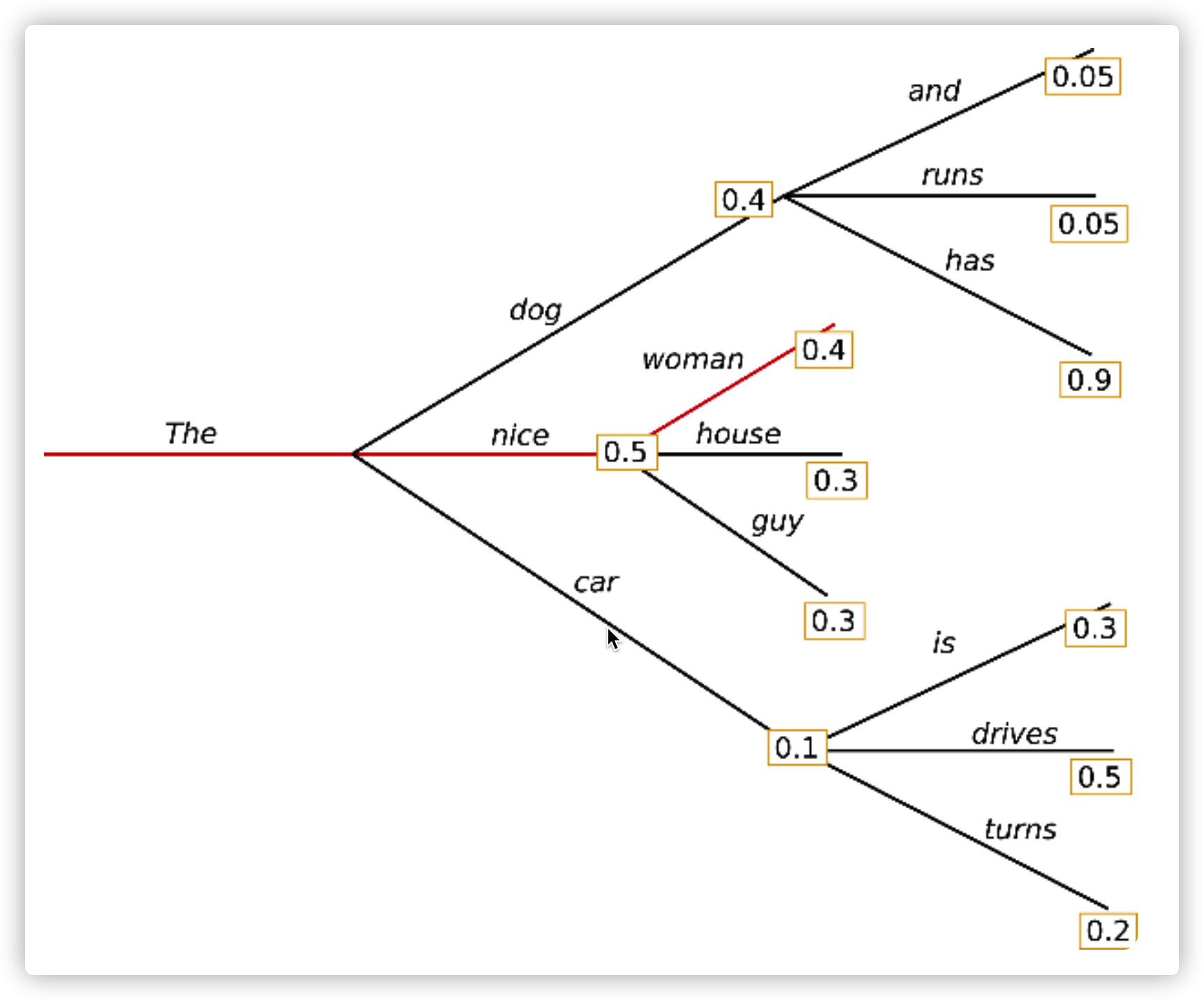
从单词“The”开始,算法在选择下一个词时,贪心的选择了概率最高的“nice”,进而,最终的生成词序列为(“The”,“nice”,“woman”),总概率为$0.5\times0.4=0.2$
接下来我们会基于以下内容用GPT2生成词序列
(“I“,”enjoy“,”walking“,”with“,”my“,”cute“,”dog“)
下面用transformers跑greedy search
# 编码初始内容
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf')
# 生成词直到长度50(包含初始内容)
greedy_output = model.generate(input_ids, max_length=50)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with my dog. I'm not sure if I'll ever be able to walk with my dog.
I'm not sure if I'll好了,我们已经完成了用GPT2生成短文本😊。生成的词接在原文后面还算合理,但是它总是在重复自己。这在当前的语言生成模型中很常见,尤其是greedy search和beam search,详见Vijayakumar et al., 2016和Shao et al., 2017。
greedy search的主要缺点是,它只考虑了当前的高概率词,忽略了在当前低概率词后面的高概率词。就像上图中我们看到的:
词“has”在词“dog”后面,条件概率高达0.9,但词“dog”的条件概率只排第二,所以greedy search错过了词序列“The”、“dog”、“has”。
那么接下来beam search可以解决这类问题
Beam Search
beam search通过参数num_beams的配置,可以在每个时刻,记录概率最高的前几个路径,在下一个时刻可以有多个基础路径同时搜索。因此可以避免错过隐藏的高概率词。以num_beams=2为例:
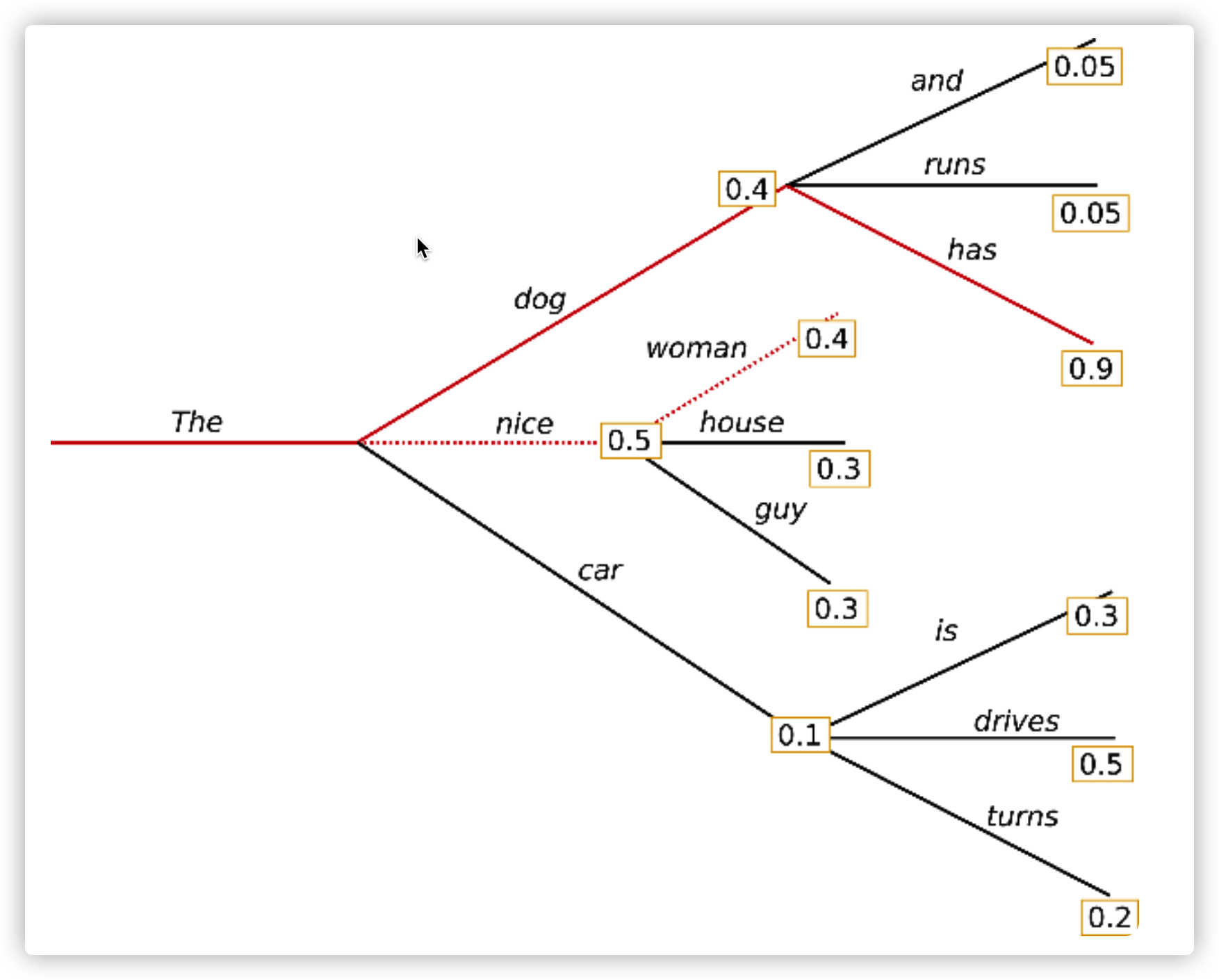
在步骤1,最大概率的路径是(“The”、“nice”),beam search同时也会记录概率排第二的路径(“The”、“dog”)。在步骤2,beam search也会发现路径(“The”、“dog”、“has”)有0.36的概率超过了路径(“The”、“nice”、“women”)的概率0.2。因此它在我们的例子中找到了概率最高的路径。
beam search生成的词序列比greedy search生成的词序列的综合概率更高,但是也不能保证是概率最高的词序列。
下面我们用transformers实现beam search,设置num_beams > 1、early_stopping=True,保证当遇到$EOS$词时,结束生成。
# 激活beam search和提前停止
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I'm not sure if I'll ever be able to walk with him again. I'm not sure if I'll这个结果看起来更流利一点,但仍然存在重复自己的情况。
一个简单的方法是用来自论文Paulus et al. (2017)和Klein et al. (2017)的n-grams惩罚。通常的n-grams惩罚通过配置下一个词重复出现n-gram的概率为0,来保证没有n-gram出现两次。
下面我们来配置no_repeat_ngram_size=2,保证不会出现重复的2-gram。
# 配置 no_repeat_ngram_size = 2
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to take a break很好,生成结果看起来更棒了,重复自己的现象不再存在了。然而,n-gram惩罚的使用要特别注意。比如一篇关于城市New York的文章的生成不能配置2-gram惩罚,否则整篇文章就只能出现这个城市名一次。
另一个关于beam search的重要点是,我们可以比较多组生成结果,选择最符合的结果。
在transformers中,我们配置参数num_return_sequences,返回综合概率最高的几个生成结果,要注意num_return_sequences <= num_beams!
# set return_num_sequences > 1
beam_outputs = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences=5,
early_stopping=True
)
# now we have 3 output sequences
print("Output:\n" + 100 * '-')
for i, beam_output in enumerate(beam_outputs):
print("{}: {}".format(i, tokenizer.decode(beam_output, skip_special_tokens=True)))Output:
----------------------------------------------------------------------------------------------------
0: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to take a break
1: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to get back to
2: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with her again.
I've been thinking about this for a while now, and I think it's time for me to take a break
3: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with her again.
I've been thinking about this for a while now, and I think it's time for me to get back to
4: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to take a step可以看到,这五条生成结果彼此都有所不同
在开放领域生成任务的很多时候,beam search都不是最好的解码方式:
beam search在做像是翻译和摘要这类可以大致预测生成长度的场景中表现还可以Murray et al. (2018)、Yang et al. (2018)。但是在像是对话和故事生成这类开放生成领域效果就差得多了。
我们已经看到beam search经常会生成重复内容,在故事生成中,我们很难决定要不要n-gram惩罚,因为我们很难确定强制不要重复还是有重复会更好。
Ari Holtzman et al. (2019)提到,高水平的人类语言不会按照下一个词条件概率最高的方式排列。换言之,我们人类的语言会经常让你意外,而不是每个词都是无聊的、可预测的。这篇论文画出了人类语言和beam search生成的概率分布如下↓
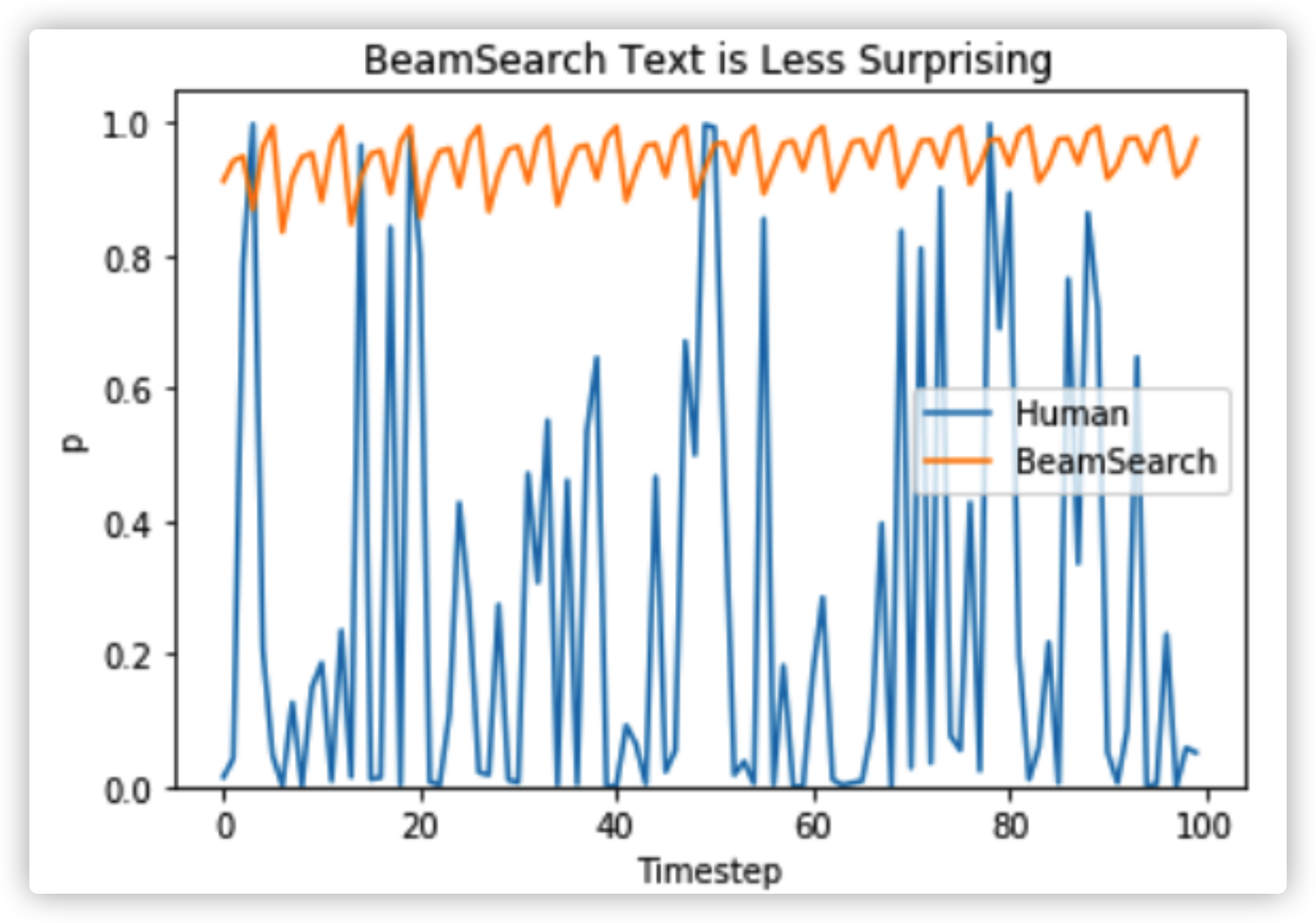
那么接下来,我们开始在文本生成中,加一点随机性😜
Sampling
在大多数场景,Sampling意味着从已有词序列的条件概率分布中随机选择下一个词$w_t$
$$w_t\sim{P(w|w_{1:t-1})}$$
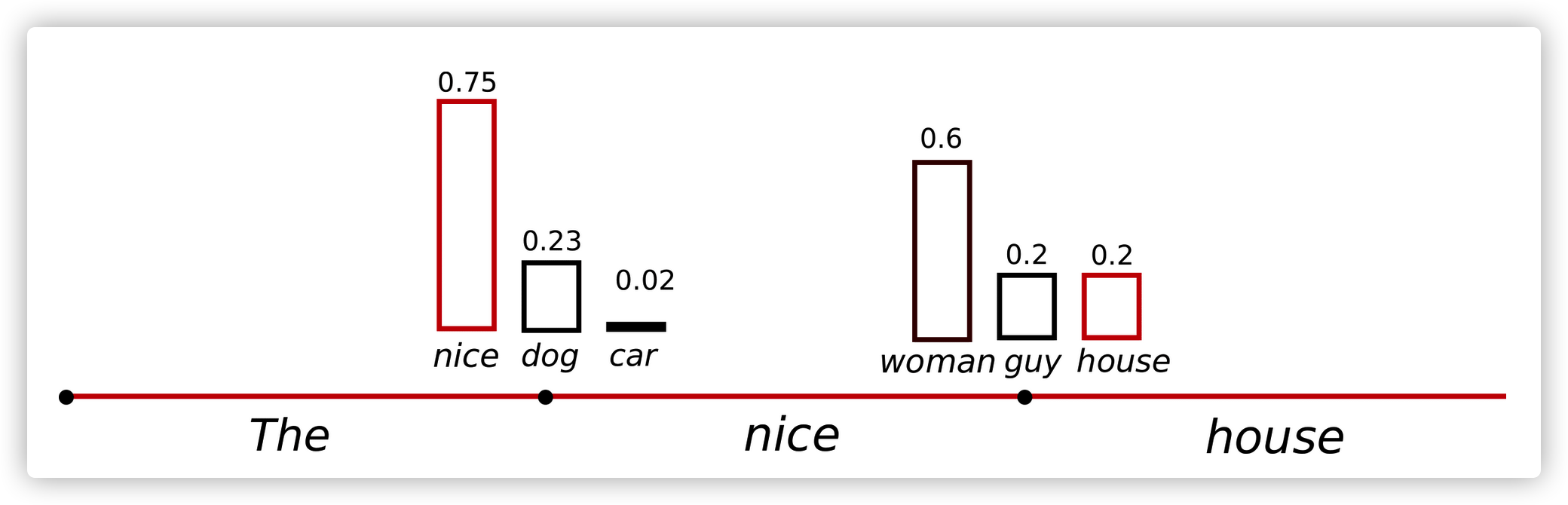
仍然以上面的例子,下面这张图可以看到sampling的语言生成效果
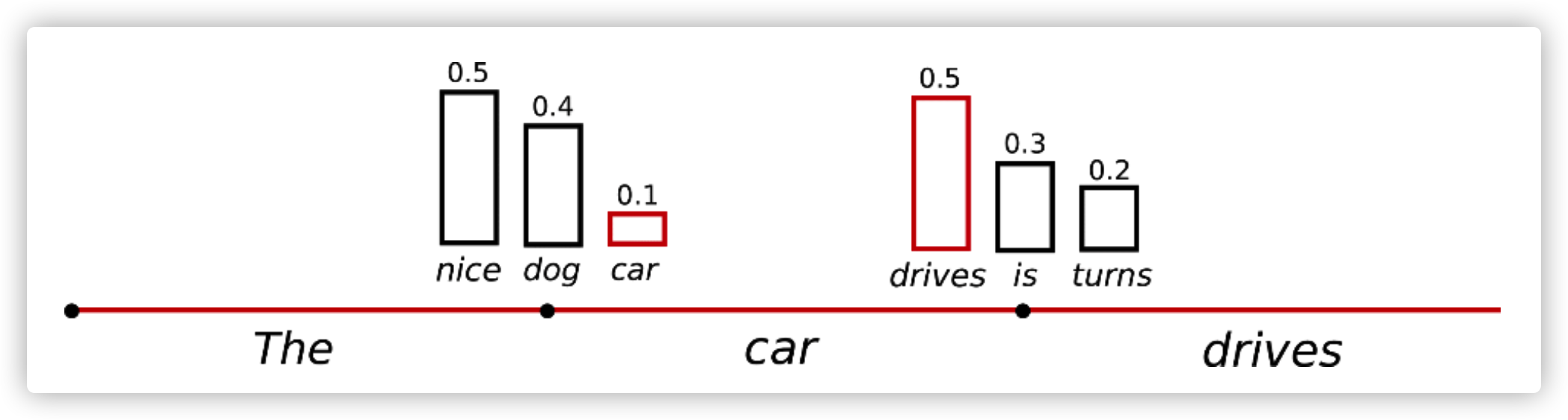
很容易看出,sampling语言生成不再是基于条件概率一成不变的,词(“car”)是在条件概率$P(w|“The”)$后面采样出来的,接下来的词(“drives”)是在条件概率$P(w|“The”,“car”)$后面采样出来的。
在transformers库中,我们可以配置do_sample=True、top_k=0、ransom_seed=0。
# 通过配置种子,可以随意的控制不同的生成结果
tf.random.set_seed(0)
# 开启sampling,关闭top_k
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog. He just gave me a whole new hand sense."
But it seems that the dogs have learned a lot from teasing at the local batte harness once they take on the outside.
"I takeNice,生成的文本看起来不错,但是仔细看,看起来仍然不是很连贯。三元组(“new”、“hand”、“sense”)(“local”、“batte”、“harness”)看起来很怪,不像是人写出来的,这在sampling生成中是一个很大的问题,同时他也经常胡言乱语 Ari Holtzman et al. (2019)。
一个小技巧是,通过把所谓的softmax
的temperature配置的更低,可以把单词分布概率$P(w|w_{1:t-1})$的高概率词的概率调的更高,低概率词调的更低。
配置temperature后的概率分布如下
在$t=1$时刻,下一个词的条件概率变得更锐了,几乎没有可能生成(“car”)。
下面的代码配置了temperature=0.7
# 通过配置种子,可以随意的控制不同的生成结果
tf.random.set_seed(0)
# 通过配置temperature,降低了低概率候选词选中的可能性
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0,
temperature=0.7
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I don't like to be at home too much. I also find it a bit weird when I'm out shopping. I am always away from my house a lot, but I do have a few friendsOK,这样出现奇怪的n-grams组的机会小多了,整体看起来更连贯了。通过配置不同的temperature,可以改变随机性,当配置$temperature\to0$,那么生成效果就回到greedy search了。
Top-K Sampling
Fan et. al (2018)介绍了一个简单有效的sampling方法,叫做Top-K sampling。在处理中,前K个条件概率最高的词被拎出来,条件概率被重新分到这前K个词中。GPT2用了这种抽样方法,这也是它生成故事效果好的主要原因。
下面我们介绍从3个词到10个词的Top-K sampling方法
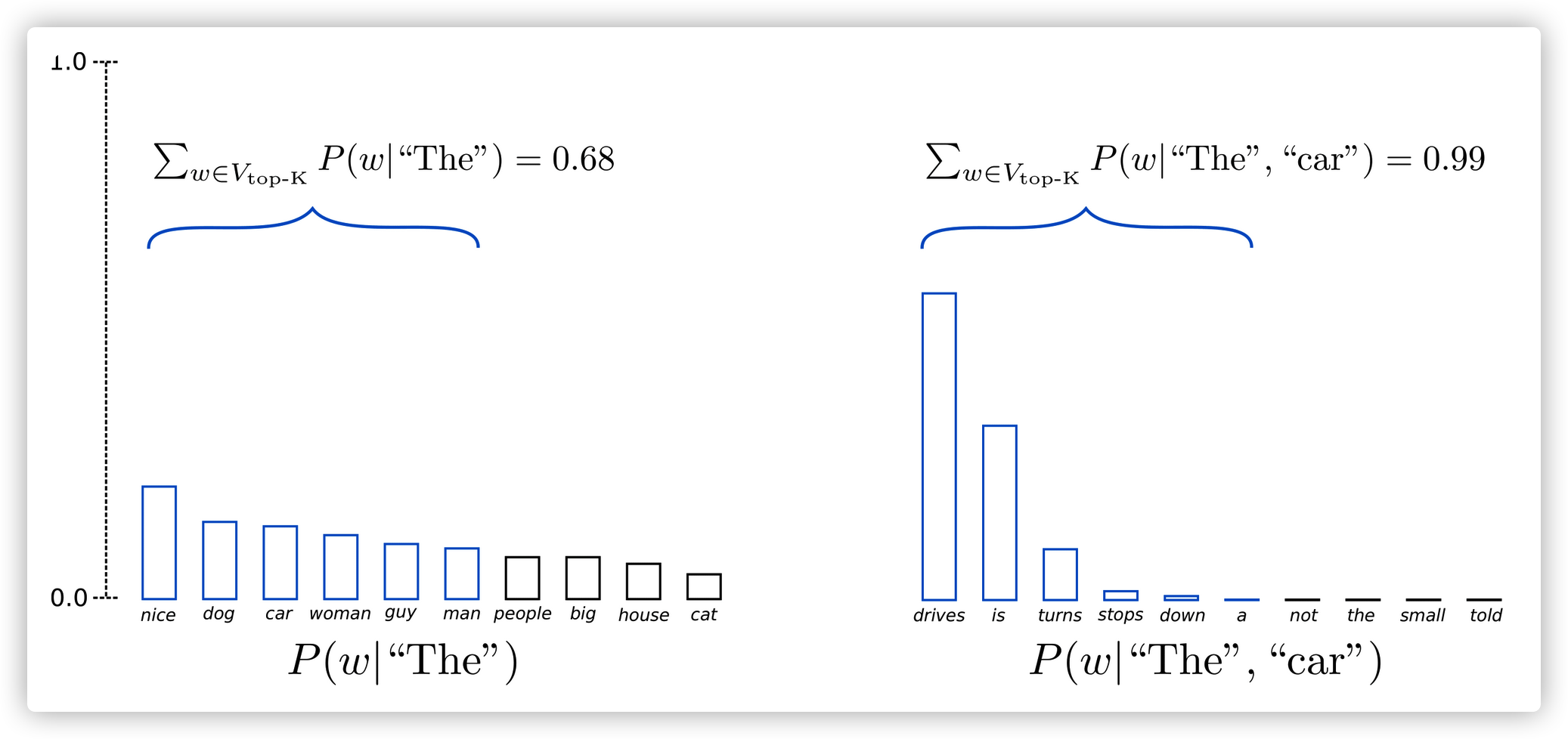
当配置$K=6$的抽样时,我们限制了候选池是概率最高的前6个词,这6个词的集合被定义为$V_{top-K}$。在第一轮他们占据全部概率的约2/3,而第二轮前6个词几乎占据了所有的概率。所以,我们避免了在第二轮生成奇怪的词,如(“not”、“the”、“small”、“told”、)。
下面我们配置top_k=50
# 通过配置种子,可以随意的控制不同的生成结果
tf.random.set_seed(0)
# 配置 top-k至50
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog. It's so good to have an environment where your dog is available to share with you and we'll be taking care of you.
We hope you'll find this story interesting!
I am from看起来不错!这段文本生成已经很像人说的话了。但还有一个问题,Top-K sampling不会根据下一个词的概率分布$P(w|w_{1:t-1})$,动态调整候选池的大小。当条件概率非常集中的时候,会更倾向于选择top-k中的词,而当条件概率非常分散的时候,就不能选中top-k以外的词了。
在步骤$t=1$时,Top-K 去掉了看起来合理的首选词(“people”、“big”、“house”、“cat”), 而在步骤$t=2$时,Top-K方法有可能选中有问题的词如(“down”、“a”)。因此,将词的候选池限定为固定大小,可能在候选词概率集中时,选中奇怪的候选词,而候选词概率分散时,又会限制模型的创造性。因此有了Ari Holtzman et al. (2019)的Top-p sampling和nucleus sampling。
Top-p(nucleus) Sampling
与限定在前K个词的采样不同的是,Top-p sampling会根据累计概率超过概率p时,从候选集选择个数最少的子集。通过这种方式,子集的大小可以动态的根据概率分布调整。下面来详细举例说明。
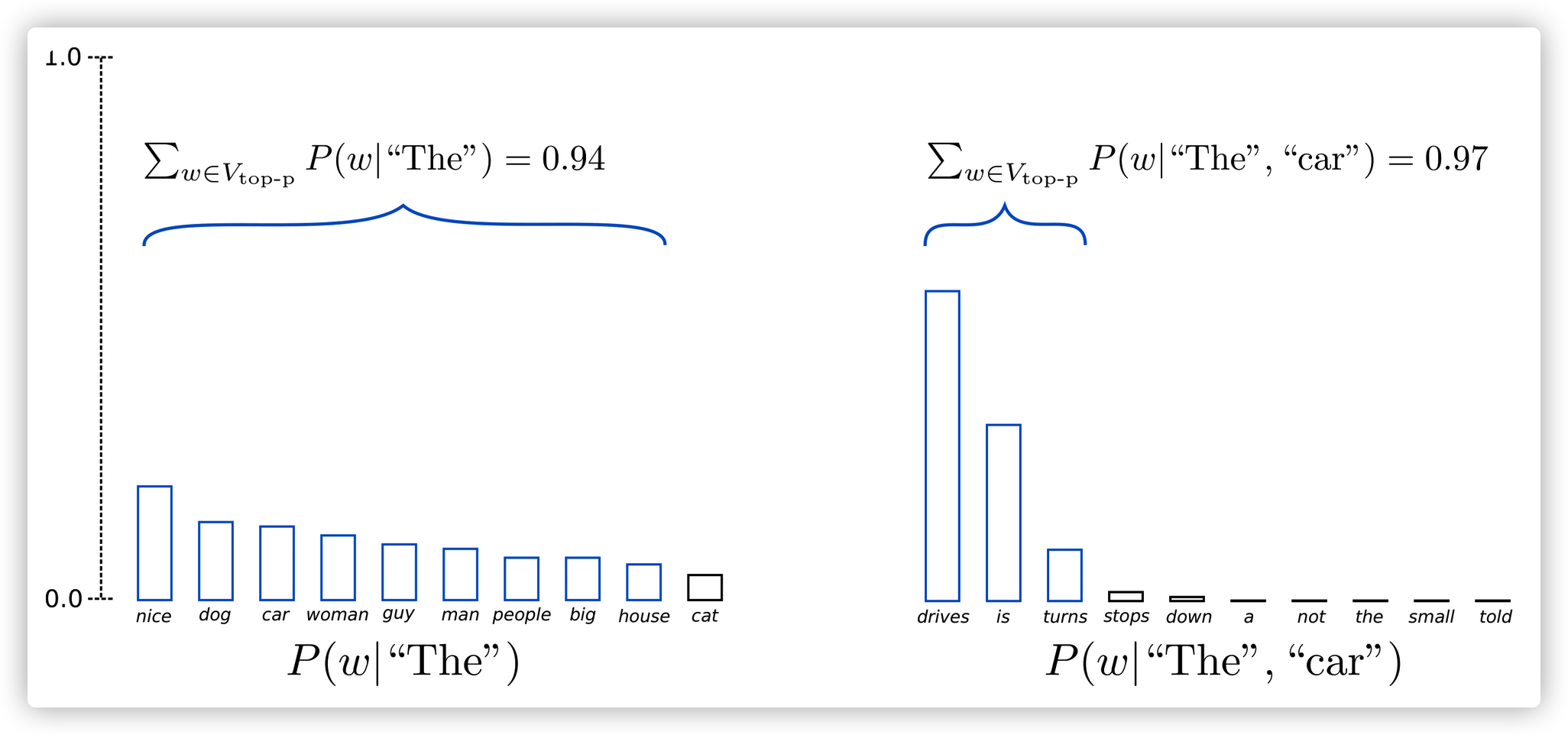
当配置$p=0.92$的抽样时,top-p sampling选择了累计概率超过92%的最少个数的子集。称为$V_{top-p}$。在第一轮中,子集包含了9个最可能的词,在第二轮中,子集为前3个词,累计概率就超过92%。也就是说,在条件概率分布分散,下一个词不易预测时,候选子集范围更大;在条件概率分布集中,下一个词容易预测时,候选子集范围更小。
在transformers中,我们可以配置$0\ <\ top-p\ <\ 1$来启动top-p sampling。
# 通过配置种子,可以随意的控制不同的生成结果
tf.random.set_seed(0)
# 关闭 top-k sampling top-p sampling累计概率至0.92
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_p=0.92,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog. He will never be the same. I watch him play.
Guys, my dog needs a name. Especially if he is found with wings.
What was that? I had a lot o很好,现在看起来更像是人说的话了。
理论上top-p sampling比top-k sampling更优雅,但两种方法都有自己的优势。top-p sampling也可以和top-k sampling结合,可以动态选择,避免选中过低概率的词。
最终,为了获得多种独立生成结果,我们可以配置参数num_return_sequences > 1。
# 通过配置种子,可以随意的控制不同的生成结果
tf.random.set_seed(0)
# 配置 top_k = 50 、 top_p = 0.95 、 num_return_sequences = 3
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50,
top_p=0.95,
num_return_sequences=3
)
print("Output:\n" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))Output:
----------------------------------------------------------------------------------------------------
0: I enjoy walking with my cute dog. It's so good to have the chance to walk with a dog. But I have this problem with the dog and how he's always looking at us and always trying to make me see that I can do something
1: I enjoy walking with my cute dog, she loves taking trips to different places on the planet, even in the desert! The world isn't big enough for us to travel by the bus with our beloved pup, but that's where I find my love
2: I enjoy walking with my cute dog and playing with our kids," said David J. Smith, director of the Humane Society of the US.
"So as a result, I've got more work in my time," he said.Cool,现在可以用transformers实现这些解码技术,生成你的故事了。
总结
在开放语言生成领域,top-p和top-k这些解码方法,比greedy search、beam search生成的文本更流利。如今,也有很多证据证明了greedy search、beam search的缺点,如生成重复的词序列,是因为训练的模型导致的,而不是解码方式Welleck et al. (2019)。同时,在Welleck et al. (2020)中,也证明了,top-K和top-p抽样也会生成重复的词序列。
在Welleck et al. (2019)中,在调整训练目标后,通过人类评测beam search和top-p sampling发现,beam search的生成文本更流利。
开放领域语言生成正在快速迭代研究中,没有通用的最优方法,只有在特定场景更适合的方法。
好消息是,你可以在transformers中,快速尝试所有的解码方法😊
以上就是用transformers实现开放领域语言生成的不同解码方法的简短介绍。
有任何反馈和问题请访问github repository。
获取更多有趣的故事生成技术Writing with Transformers
感谢这个博客的贡献者:Alexander Rush, Julien Chaumand, Thomas Wolf, Victor Sanh, Sam Shleifer, Clément Delangue, Yacine Jernite, Oliver Åstrand and John de Wasseige
附录
在语言生成时,有一些额外的参数配置没有介绍如下
- min_length可以用来强制模型在生成文本不到min_length时,不要生成EOS词。这在摘要领域很常见,而在想要生成长文本时几乎是必须要配置的。
- repetition_penalty可以被用来惩罚重复的词。这在Kesker et al. (2019)中第一次提到,在Welleck et al. (2019)中被用于训练目标。它在防止重复序列时很有用,但在不同的生成模型和案例中,情况又很复杂github。
- attention_mask可以用来遮住补位词(<pad>)。
- pad_token_id、bos_token_id、eos_token_id:如果模型这些特别的词不是默认的,可以手动配置。
更多的生成函数请查看文档docstring



