简要
这是一个实验记录,用GPU搭建flask服务器的资源释放优化过程
跑cpu的模型
服务中跑模型训练时,从主进程分出子进程运行模型训练代码
import multiprocessing as mp
while True:
_param = self.q.get()
model_prefix = _param["appid"]
p = mp.Process(
target=self.sync_train,
name=model_prefix,
args=(
_param["appid"],
_param["data"],
_param["config"],
_param["model_train"],
),
)
p.start()运行结束后通过杀死该进程回收资源
killRs = os.kill(pid, signal.SIGKILL)跑gpu的模型
直接套用后报错:
RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the 'spawn' start methodThe CUDA runtime does not support the fork start method; either the spawn or forkserver start method are required to use CUDA in subprocesses.
查看python官方文档关于multiprocessing的fork、spawn、forkserver启动模式的解释
> Depending on the platform, multiprocessing supports three ways to start a process. These start methods are
> spawn:
> The parent process starts a fresh python interpreter process. The child process will only inherit those resources necessary to run the process objects run() method. In particular, unnecessary file descriptors and handles from the parent process will not be inherited. Starting a process using this method is rather slow compared to using fork or forkserver.
> Available on Unix and Windows. The default on Windows.
> fork:
> The parent process uses os.fork() to fork the Python interpreter. The child process, when it begins, is effectively identical to the parent process. All resources of the parent are inherited by the child process. Note that safely forking a multithreaded process is problematic.
> Available on Unix only. The default on Unix.
> forkserver:
> When the program starts and selects the forkserver start method, a server process is started. From then on, whenever a new process is needed, the parent process connects to the server and requests that it fork a new process. The fork server process is single threaded so it is safe for it to use os.fork(). No unnecessary resources are inherited.
> Available on Unix platforms which support passing file descriptors over Unix pipes.由此可知Unix系统的multiprocessing默认采用fork模式,想要在子进程中启动CUDA,必须改成spawn、forkserver模式。
在启动服务时,加入代码,设置spawn模式:
if __name__ == "__main__":
set_start_method('spawn')
app.run(host="0.0.0.0", port=10001, debug=False, threaded=False)发现启动服务时,报错:
RuntimeError: context has already been set查资料后,在set_start_method中加入force=True:
if __name__ == "__main__":
set_start_method('spawn', force=True)
app.run(host="0.0.0.0", port=10001, debug=False, threaded=False)此时服务生成子进程时又报错
typeerror: can't pickle _thread.lock objects process查资料说生成子进程时共享变量不能序列化,这是一个python多进程时常见的问题。
有的帖子说从3.8退回3.7解决了pickle问题
于是我尝试了python3.6、3.7、3.8都不能解决问题
考虑到服务代码中,传入子进程中的变量一定要包含自定义的对象,所以没办法,放弃了服务用子进程跑gpu的方式。
改成子线程启动模型训练
从主进程中分出来线程训练模型,把multiprocessing.Process改为threading.Thread。
考虑到GPU资源问题,一次只能训练一个模型,所以在后面加上p.join()
import threading
while True:
_param = self.q.get()
model_prefix = _param["appid"]
p = threading.Thread(
target=self.sync_train,
name=model_prefix,
args=(
_param["appid"],
_param["data"],
_param["config"],
_param["model_train"],
),
)
p.start()
p.join()但是如果按照刚才的思路,当训练结束后,用kill进程的方式,回收资源,那么杀掉的是主进程,即整个服务就被kill了
- 尝试把kill进程改为kill线程
In general, killing threads abruptly is considered a bad programming practice. Killing a thread abruptly might leave a critical resource that must be closed properly, open.
- 寻找pytorch的命令直接释放显卡资源
torch.cuda.empty_cache()在服务的启动的线程中,模型训练结束后运行该命令后发现:
nvidia-smi中资源并没有全部释放,从训练时的7000MiB,下降至3000MiB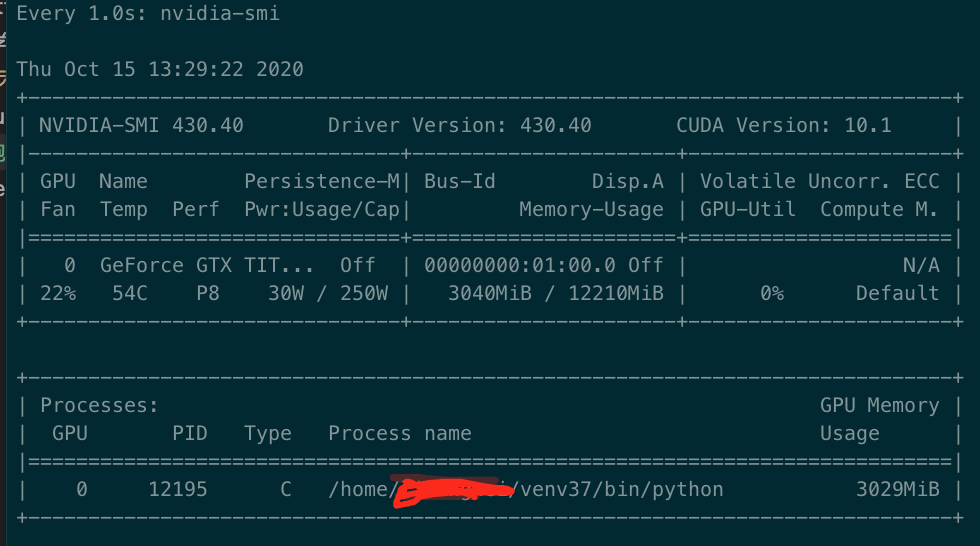
继续查资料后发现这篇帖子说,显存已经清零了,只是在nvidia-smi中没有显示清零而已。
于是半信半疑的让该服务执行了很多次训练模型,果然每次训练时,占用内存都是固定的。
该命令的确实际清零了显存。