背景
最近刷到一篇博客,吐槽torchtext不能做多标签任务,特来为torchtext鸣不平,看好,我要用torchtext做多标签任务了。
简要
- 解读
- torchtext库,做多标签任务
- 实践
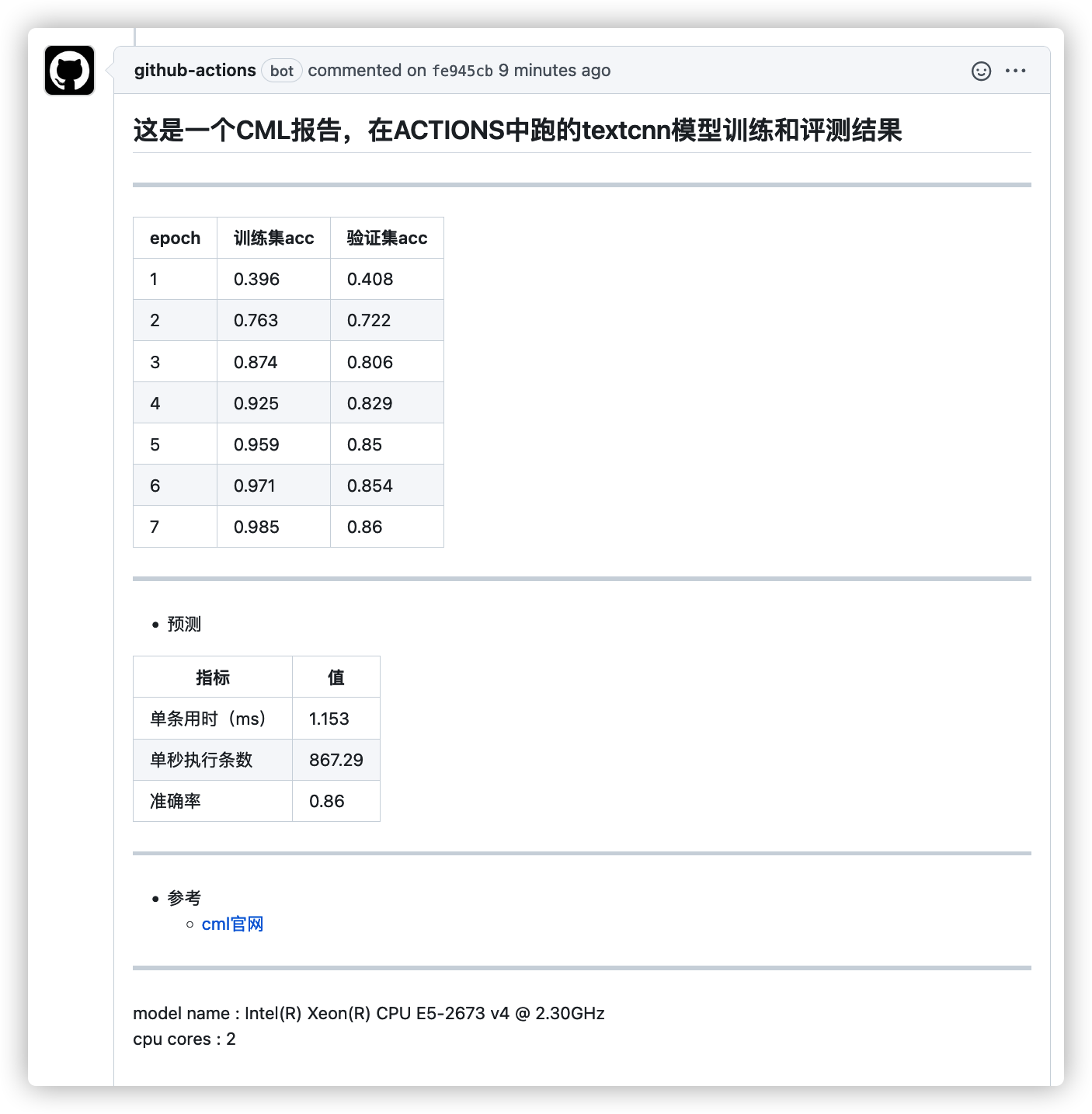
- textcnn模型,跑百度事件多标签比赛,验证集准确率accuracy达到
86%
- textcnn模型,跑百度事件多标签比赛,验证集准确率accuracy达到
- 运行
github的action中,完成全程训练、批测,结果报告通过cml工具发送至commit评论
解读
- 如何用torchtext库,做多标签任务
读取数据
顾名思义,多标签任务像是不定项选择题,是一条样本对应一个或多个标签,也可以没有对应标签,所以标注字段不能再用sequential=False参数,要对标注列进行切分,源码中的注释说明:
sequential: Whether the datatype represents sequential data. If False, no tokenization is applied. Default: True.
写入标签数据
<pad>表示占位符没有任何意义
echo -e "label\n汽车&&银行\n汽车&&天气\n天气\n<pad>\n咖啡" > label.tsv字段设置
以&&切分标注标签,那么可以这样写:
label = torchtext.data.Field(
tokenize=lambda x: x.split("&&"), unk_token=None
)
读取Dataset
dataset = torchtext.data.TabularDataset(
path="label.tsv",
format="tsv",
skip_header=True,
fields=[("label", label)],
)
print(dataset.examples[0].__dict__)
print(dataset.examples[1].__dict__)
print(dataset.examples[2].__dict__)
print(dataset.examples[3].__dict__)
print(dataset.examples[4].__dict__){‘label’: [‘汽车’, ‘银行’]}
{‘label’: [‘汽车’, ‘天气’]}
{‘label’: [‘天气’]}
{‘label’: [“<pad>“]}
{‘label’: [“咖啡”]}
建立标签id映射表
label.build_vocab(dataset)
with open("label_dict.json", "w") as f:
json.dump(
dict(label.vocab.stoi),
f,
indent=4,
ensure_ascii=False
)
print(label.vocab.stoi){‘
<pad>‘: 0, ‘天气’: 1, ‘汽车’: 2, ‘咖啡’: 3, ‘银行’: 4}
读取Iterator
train_iter = torchtext.data.BucketIterator(
dataset,
device="cpu",
repeat=False,
batch_size=2,
sort=False,
shuffle=True,
)
for batch in train_iter:
print(batch.label)# 注意这里每一列是一个样本
tensor([[2],
[4]]) # 汽车、银行;
tensor([[2, 1],
[1, 0]]) # 汽车、天气;天气、<pad>
tensor([[3, 0]]) # 咖啡;<pad>损失函数
- 多分类任务相当于
单选题,每个标签是互斥的,预测整个logits在这个标签体系上做softmax,然后计算交叉熵损失函数; - 多标签任务相当于
不定项选择题,每个标签是独立的,每个标签位置的logit做sigmoid,然后单独计算交叉熵损失函数,然后再求和; - pytorch已经包装好多标签任务的损失函数BCEWithLogitsLoss
torch.nn.BCEWithLogitsLoss标注标签转onehot格式
- 当前从生成器BucketIterator出来的batch数据,是标签id,需要把它映射成
onehot格式便于计算Loss
def multi_label_metrics_transfer(self, y, label_num):
"""
输入 torchtext 的多分类标签体系,0表示占位符没有意义
tensor([[1, 1, 1, 2, 1, 1, 1, 1, 1],
[2, 3, 2, 1, 0, 2, 2, 0, 2],
[0, 0, 3, 0, 0, 0, 0, 0, 0]])
输出 onehot多标签矩阵
tensor([[1., 1., 0.],
[1., 0., 1.],
[1., 1., 1.],
[1., 1., 0.],
[1., 0., 0.],
[1., 1., 0.],
[1., 1., 0.],
[1., 0., 0.],
[1., 1., 0.]])
"""
return torch.zeros(
y.shape[1],
label_num,
dtype=torch.float,
device=self.config.device,
).scatter_(
1,
y.T,
torch.ones(
y.shape[1],
label_num,
dtype=torch.float,
device=self.config.device,
),
)[
:, 1:
]实践
统计
| 数据项目 | 统计值 |
|---|---|
| 训练集单条jieba分词个数均值 | 31.63 |
| 训练集单条jieba分词个数98%分位 | 101 |
| 训练集条数 | 11958 |
| 验证集条数 | 1498 |
| jieba分词去重个数 | 40113 |
| 标签个数 | 65 |
因此模型最大长度设置100
词向量sgns_百度.pt是来自词向量sgns.merge.word中,训练集出现过的词汇、以及原词向量中词频最高的前10000个词
运行