简要
本文记录了在同样硬件设备上的pytorch与tensorflow的推断对比,仅供参考。
数据
cpu:20核
gpu:1080
跑一百次推断平均花费时间(ms)
| token个数 | tf_cpu(v: 2.3.0) | tf_gpu(v: 2.3.0) | tf_cpu(v: 2.2.0) | tf_gpu(v: 2.2.0) | torch_cpu(v: 1.6.0) | torch_gpu(v: 1.6.0) |
|---|---|---|---|---|---|---|
| 6 | 105.715 | 99.1848 | 55.2186 | 38.4081 | 43.7772 | 16.8197 |
| 10 | 83.45 | 73.3169 | 34.24 | 15.18 | 45.076 | 17.0497 |
| 20 | 99.7447 | 73.1447 | 34.1811 | 13.8295 | 45.076 | 17.1007 |
| 40 | 145.19 | 97.3115 | 75.4963 | 14.2891 | 40.396 | 17.8771 |
| 80 | 214.368 | 122.786 | 94.2401 | 16.0448 | 57.2286 | 18.3441 |
| 160 | 382.322 | 192.375 | 147.581 | 18.5755 | 205.225 | 20.4077 |
| 320 | 683.065 | 315.605 | 202.082 | 28.3363 | 301.291 | 22.2123 |
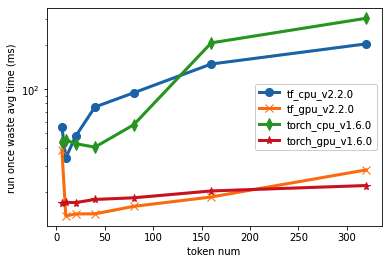
结论
- tf 2.2.0、torch 1.6.0相差不多
- tf 2.3.0有坑,性能巨慢
代码
tf
from bert4keras.backend import keras
from bert4keras.models import build_transformer_model
from bert4keras.tokenizers import Tokenizer
from bert4keras.snippets import to_array
from tqdm import tqdm
import numpy as np
import tensorflow as tf
config_path = '/home/llw/uncased_L-12_H-768_A-12/bert_config.json'
checkpoint_path = '/home/llw/uncased_L-12_H-768_A-12/bert_model.ckpt'
dict_path = '/home/llw/uncased_L-12_H-768_A-12/vocab.txt'tf cpu
from datetime import datetime
ns = [6,10,20,40,80,160,320]
with tf.device('/cpu:0'):
tokenizer = Tokenizer(dict_path, do_lower_case=True) # 建立分词器
model = build_transformer_model(config_path, checkpoint_path) # 建立模型,加载权重
dts = []
for n in ns:
dt = datetime.now()
for i in tqdm(range(100)):
token_ids, segment_ids = to_array(tokenizer.encode(u'this is '*int(n/2)))
model.predict([[token_ids], [segment_ids]])
delta = datetime.now()-dt
dts.append((delta.seconds+delta.microseconds/1000/1000)*10)tf gpu
with tf.device('/gpu:0'):
tokenizer = Tokenizer(dict_path, do_lower_case=True) # 建立分词器
model = build_transformer_model(config_path, checkpoint_path) # 建立模型,加载权重
dts2 = []
for n in ns:
dt = datetime.now()
for i in tqdm(range(100)):
token_ids, segment_ids = to_array(tokenizer.encode(u'this is '*int(n/2)))
model.predict([[token_ids], [segment_ids]])
delta = datetime.now()-dt
dts2.append((delta.seconds+delta.microseconds/1000/1000)*10)torch
from transformers import AutoTokenizer, AutoModel
from datetime import datetime
from tqdm import tqdm
tokenizer = AutoTokenizer.from_pretrained("/home/llw/en_faq/models/bert-base-uncased/")
model = AutoModel.from_pretrained("/home/llw/en_faq/models/bert-base-uncased/")torch cpu
dts3 = []
for n in ns:
dt = datetime.now()
for i in tqdm(range(100)):
inputs = tokenizer(u'this is '*int(n/2), return_tensors="pt")
outputs = model(**inputs)
delta = datetime.now()-dt
dts3.append((delta.seconds+delta.microseconds/1000/1000)*10)torch gpu
model.to('cuda')
dts4 = []
for n in ns:
dt = datetime.now()
for i in tqdm(range(100)):
inputs = tokenizer(u'this is '*int(n/2), return_tensors="pt").to('cuda')
outputs = model(**inputs)
delta = datetime.now()-dt
dts4.append((delta.seconds+delta.microseconds/1000/1000)*10)plot
import pandas as pd
df = pd.DataFrame({'tf_cpu':dts,'tf_gpu':dts2,'torch_cpu':dts3,'torch_gpu':dts4},index = ns)
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
markers = ['o','x','d','*']
for i, column in enumerate(df.columns):
ax.plot(df.index, df[column], marker=markers[i], linewidth=3, MarkerSize=8, label=column)
plt.legend()
ax.set_ylabel('run once waste avg time (ms)')
ax.set_xlabel('token num')
plt.show()