资源
引子
随着机器学习数据集统一平台的快速发展(Lhoest et al. 2021),HuggingFace团队开始探索如何管理数据集文档(McMillan-Major et al., 2021)。文档是认识数据集必要的第一步,通过文档我们知道如何统计和查看这份数据集,动态观察数据集的不同角度。
在这里,我们介绍一个开源Python库和零代码界面,名为Data Measurements Tool。通过Dataset和Spaces社区,搭配Streamlit tool工具,它可以用来帮助理解、构建、洞察和比较数据集。
什么是Data Measurements Tool?
Data Measurements Tool (DMT)是一个交互页面和开源库,帮助作者和用户自动的统计有意义的数值。
我们为什么做这个工具
在AI技术中,我们经常忽视研究和分析数据集本身。尤其在大数据和AI结合的今天,源数据来自大量的不同网站,格式风格差别很大,而当前工作范式(Luccioni et al., 2021, Dodge et al., 2021)很少花费精力计算不同数据源的数据差别,也很少清楚这些差别是如何影响模型训练的。尽管数据标注可以帮助治理数据集,使得其更符合开发人员的目标,但测量这些数据集的不同方法显的远远不够(Sambasivan et al., 2021)。
新一波AI研究呼吁,处理数据集的方式需要根本性改变 (Paullada et al., 2020, Denton et al., 2021),这包括数据集构建前的需求细化(Hutchinson et al., 2021),围绕问题和反馈的数据集治理(Yang et al., 2020,Prabhu and Birhane, 2020),以及明确数据集构建和维护的内在价值 (Scheuerman et al., 2021,Birhane et al., 2021)。大家普遍认同数据集开发是一个复杂任务,需要开发者遵循很多制度,但是因为分析搜索数据集需要复杂的编程能力,所以现实情况是处理原始数据本身存在一定瓶颈。
如今很少有公开工具,可用来方便的统计比较数据集,我们的这份工具就是为了填补这个空白。我们研究了一些工具如Know Your Data和Data Quality for AI,以及关于数据集文档的一些科研论文Vision and Language Datasets (Ferraro et al., 2015), Datasheets for Datasets (Gebru et al, 2018), Data Statements (Bender & Friedman 2019)。然后做了一个数据集统计开源工具,和一个数据集分析的零代码页面。
什么时候使用DMT工具
Data Measurements Tool可以用来迭代探索一份或多份NLP数据集,支持从零开始的数据集的迭代开发。通过对数据集的研究和开发,提供可操作的洞察意见,帮助用户深入观察数据集的深度信息和专业角度。
使用DMT工具可以得到什么
数据集的深度观察
这里可以帮我们回答一些问题,这数据集是什么,有遗漏项吗?和预期有多少差距?
- 数据集描述
- 缺失值数量
数据集的表面特征
这里可以帮我们回答一些问题,数据集用词分布如何?
- 数据集用了多少个不同词,词的分布,包含开发性词和封闭性词。
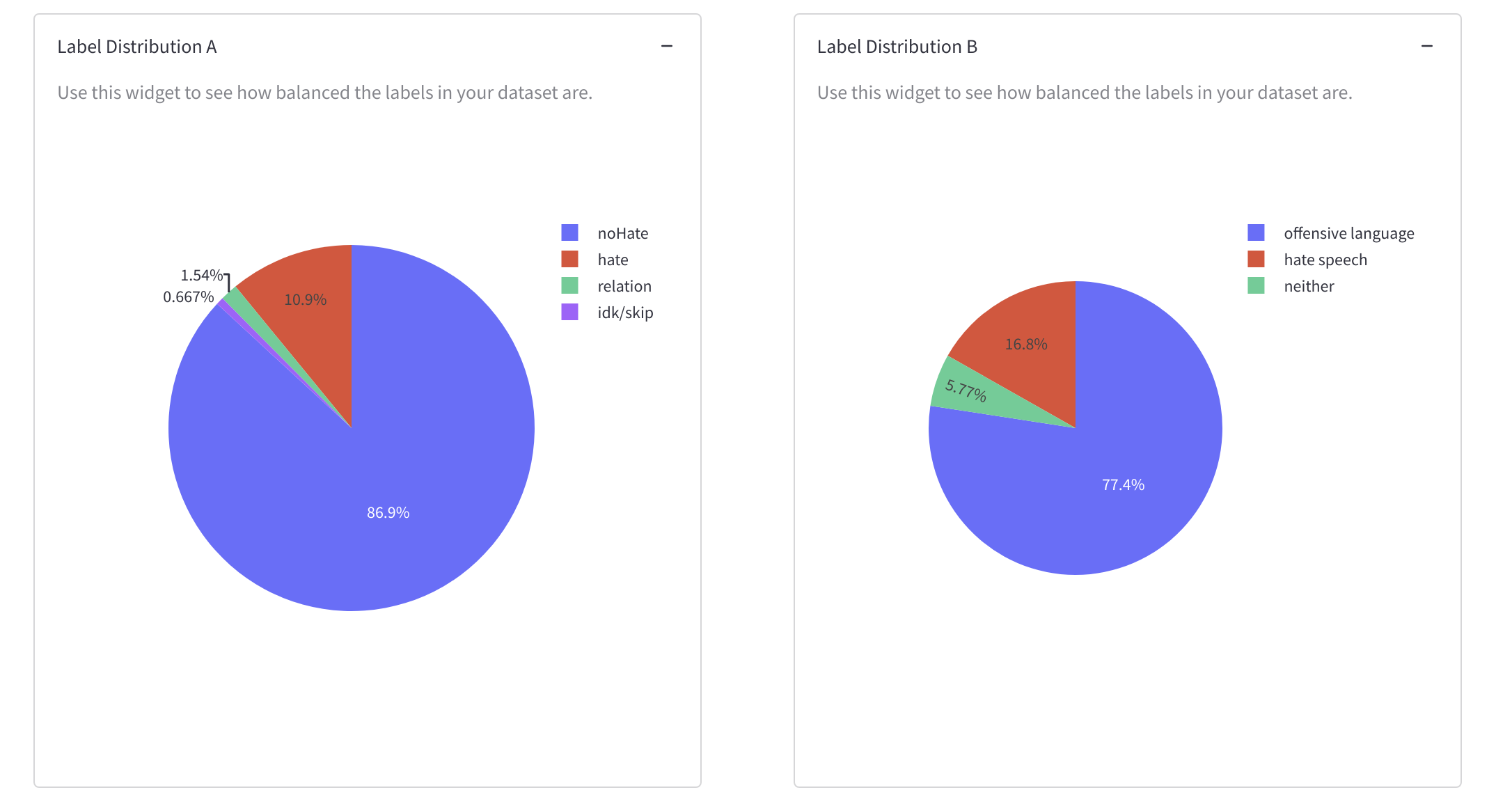
- 数据集的标签分布,是否均衡
- 文本长度的平均值、中位数、长度和分布
- 数据集样本的重复次数
使用这些图表,可以对数据集有一个初步认识。这些统计可以帮助开发者辨别,是否数据集的内容都是有用的,是否标签分布和文本长度分布是均衡的。这些也可以帮助开发者找到想要删掉的异常的重复的数据。
测量数据集语言特点
这里可以帮我们回答一些问题,数据集语言特点是什么?
- 观察词频分布,对比齐普夫定律曲线。
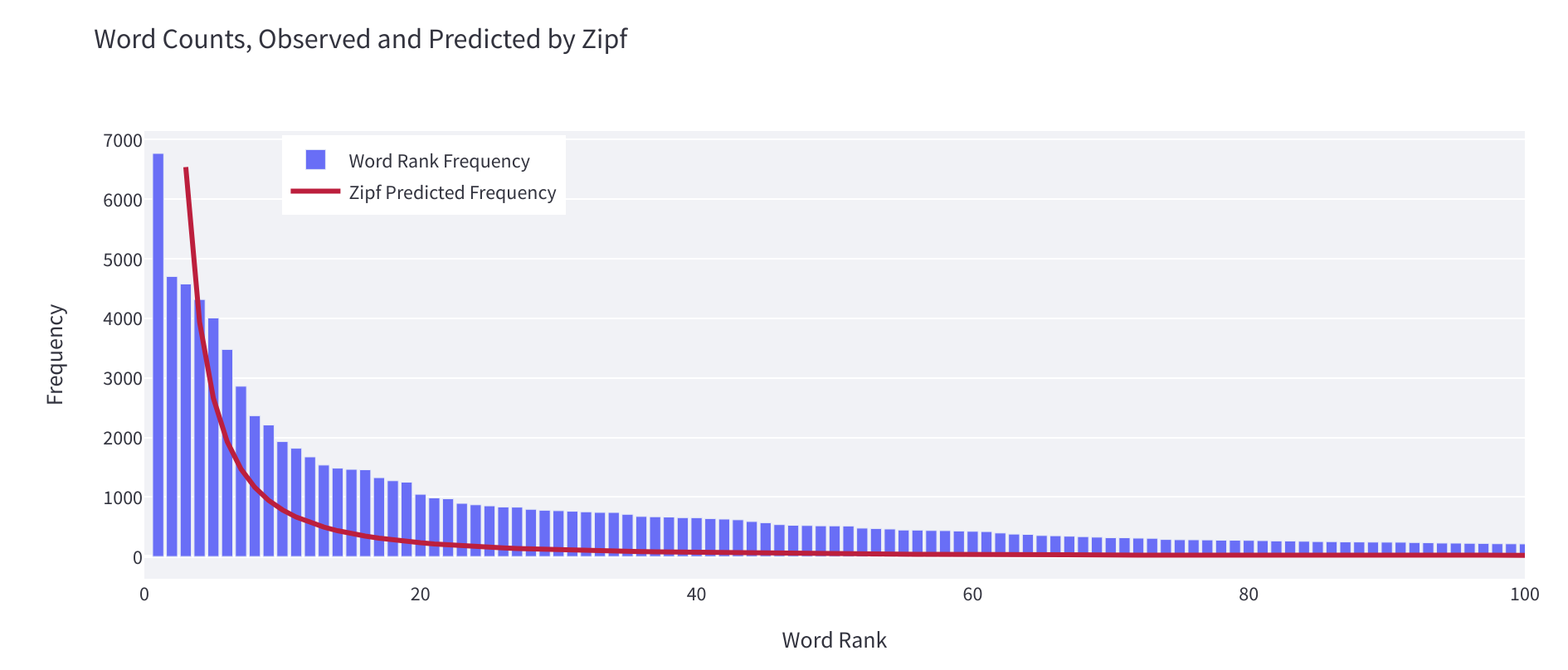
通过上图可以观察到,数据集的语言分布是否接近自然规律。如果在意数据集是否符合自然规律,可以观察计算alpha值,在下一版开发中使其逐步接近1。在不同语种中,齐普夫定律的alpha值实际也是不同的。
一般来说,alpha值超过2或者最小排序超过10,意味着数据集的语言特点是不符合自然规律的。这可能意味着有一些人工标记,如HTML富文本。你需要清洗数据集或者指导开发者判断这种人工标记还有多少。
比较统计
这里可以帮我们回答一些问题,数据集内部有什么主题、倾向、关联
- 编码聚类可以集合相似语言的样本,尤其是当处理成百上千句、风格迥异的数据集时。通过测量相似性,将其分类,可以帮助用户洞察他们的分布。我们基于sentence-transformer模型和single-linkage criterion层次聚类做了数据集文本聚类。在聚类中可以:
- 查看前5个去重后最有代表性的样本
- 输入一段文本可以找到最接近的类别
- 选择一个类id,查看该类中所有例子
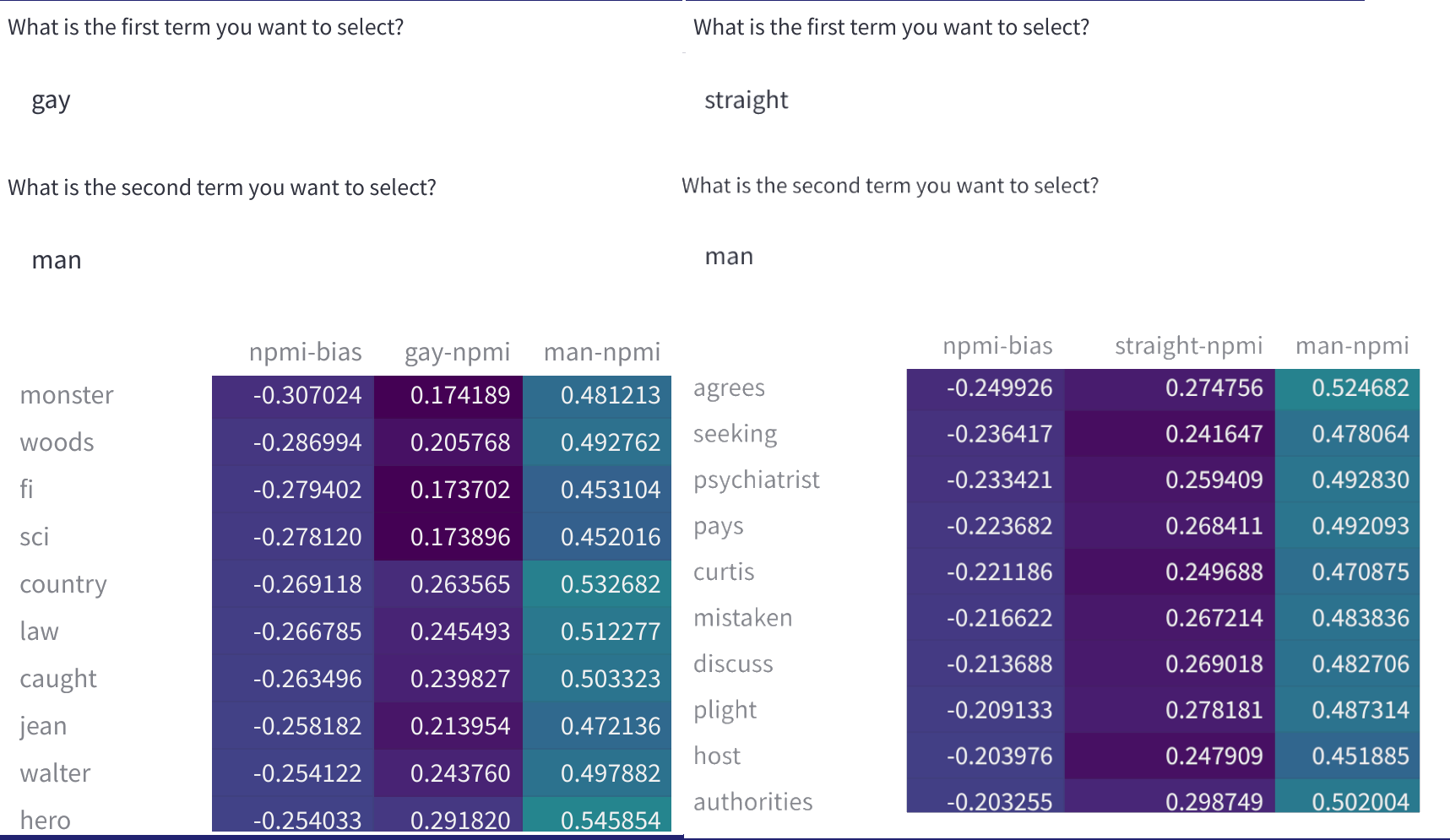
- 数据集词对的nPMI值,也可以用来分辨潜在的歧视偏见。
DMT当前的开发状态
当前处于alpha版本,该工具已经证明了在常见的英文数据集上是有用的,以上描述的功能在Dataset Hub上可以直接使用。可视化的nPMI还在开发中。
接下来的几周几个月里,DMT工具会:
- 覆盖更多语种
- 支持用户提供数据集和迭代开发数据集
- 增加更多功能,如可视化nPMI



