简要
上接Transformers仓库解读之序,对transformers库中的DataCollator的子类进行调用介绍
DataCollator
transformers的DataCollator的几个类,都是用于对原始数据集进行前处理,得到做特定任务的数据形式。
| 类名 | 继承 | 用途 |
|---|---|---|
| DataCollatorMixin | 用于判断处理哪种矩阵torch、tensorflow、numpy | |
| DefaultDataCollator | DataCollatorMixin | 默认Collator,在父类基础上,指定只处理torch矩阵 |
| DataCollatorWithPadding | 仅对输入的batch个tokens,进行padding到指定统一长度 | |
| DataCollatorForTokenClassification | DataCollatorMixin | 序列标注 |
| DataCollatorForSeq2Seq | 翻译、摘要、文本生成 | |
| DataCollatorForLanguageModeling | DataCollatorMixin | |
| DataCollatorForWholeWordMask | DataCollatorForLanguageModeling | |
| DataCollatorForSOP | DataCollatorForLanguageModeling | |
| DataCollatorForPermutationLanguageModeling | DataCollatorMixin |
DataCollatorMixin(父类)
- 根据输入
return_tensors决定处理哪种矩阵torch、tensorflow、numpy - 不直接使用
DefaultDataCollator
- 继承
DataCollatorMixin - 指定只用torch
- 不直接使用
DataCollatorWithPadding
- 仅对输入的
input_ids、attention_mask等矩阵特征做padding处理,截断或补充padding,使长度统一。
原始编码tokens
from transformers import DataCollatorWithPadding, BertTokenizer t = BertTokenizer.from_pretrained("hfl/chinese-roberta-wwm-ext") dc = DataCollatorWithPadding(t) raw_tokens = t(['我爱北京','我爱北京天安门']) raw_tokens{‘input_ids’: [[101, 2769, 4263, 1266, 776, 102], [101, 2769, 4263, 1266, 776, 1921, 2128, 7305, 102]], ‘token_type_ids’: [[0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0]], ‘attention_mask’: [[1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1]]}
DataCollator处理的数据
dc(raw_tokens)
{‘input_ids’: tensor([[ 101, 2769, 4263, 1266, 776, 102, 0, 0, 0], [ 101, 2769, 4263, 1266, 776, 1921, 2128, 7305, 102]]), ‘token_type_ids’: tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0]]), ‘attention_mask’: tensor([[1, 1, 1, 1, 1, 1, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1]])}
- 可见短的
input_ids特征被补齐了3个0,即[PAD],attention_mask被补齐了3个0,即注意力不考虑后三个位置,token_type_ids被补齐了3个0,即都属于一类句子
DataCollatorForTokenClassification(DataCollatorMixin)
- 序列标注任务,每个
token都要预测出一个label,当一个序列的token比label多的时候,对额外的label位置添加-100处理,使得计算交叉熵时,-100位置的label损失为0不用考虑
- 原始编码tokens、labels
from transformers import BertTokenizer, DataCollatorForTokenClassification t = BertTokenizer.from_pretrained("hfl/chinese-roberta-wwm-ext") dc = DataCollatorForTokenClassification(t) features = [] for line, label in [('我爱北京', [1, 1, 1, 0]), ('我爱北京天安门', [1, 0, 1, 0, 1, 1])]: feature = t(line) feature['label'] = label features.append(feature) print(dc(features)){‘input_ids’: tensor([[ 101, 2769, 4263, 1266, 776, 102, 0, 0, 0], [ 101, 2769, 4263, 1266, 776, 1921, 2128, 7305, 102]]), ‘token_type_ids’: tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0]]), ‘attention_mask’: tensor([[1, 1, 1, 1, 1, 1, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1]]), ‘label’: tensor([[ 0, 1, 1, 1, 0, -100, -100, -100, -100], [ 0, 1, 0, 1, 0, 1, 1, -100, -100]])}
DataCollatorForSeq2Seq
- 根据第一序列预测第二序列,第二序列即为
label,一个batch内多条第二序列长度不同时,用-100进行补齐。在计算交叉熵时,-100位置的损失为0不用考虑
from src.transformers import BertTokenizer, DataCollatorForSeq2Seq
t = BertTokenizer.from_pretrained("hfl/chinese-roberta-wwm-ext")
dc = DataCollatorForSeq2Seq(t)
features = []
for line, label in [('我爱北京', '北京'), ('我爱北京天安门', '天安门')]:
feature = t(line)
feature['labels'] = t(label)['input_ids']
features.append(feature)
print(dc(features)){‘input_ids’: tensor([[ 101, 2769, 4263, 1266, 776, 102, 0, 0, 0], [ 101, 2769, 4263, 1266, 776, 1921, 2128, 7305, 102]]), token_type_ids’: tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0, 0]]), ‘attention_mask’: tensor([[1, 1, 1, 1, 1, 1, 0, 0, 0],[1, 1, 1, 1, 1, 1, 1, 1, 1]]), ‘labels’: tensor([[ 101, 1266, 776, 102, -100],[ 101, 1921, 2128, 7305, 102]])}
DataCollatorForLanguageModeling(DataCollatorMixin)
- 掩词预训练
- 默认有15%的概率选中
input_ids中的token进行掩词,然后在对应label特征中给出真实字典id的标签,label中其他位置皆为-100,即计算交叉熵损失时不考虑。 - 需要注意的是,源代码中,对
input_ids特征中被选中掩词的token有三种处理方式- 80%被换成
[MASK]即字典id为103 - 10%被随机换成其他token
- 10%不做任何处理
- 80%被换成
from transformers import BertTokenizer, DataCollatorForLanguageModeling
t = BertTokenizer.from_pretrained("hfl/chinese-roberta-wwm-ext")
dc = DataCollatorForLanguageModeling(t)
features = [t('我爱北京'), t('我爱北京天安门')]
print(dc(features)){‘input_ids’: tensor([[ 101, 103, 4263, 1266, 776, 102, 0, 0, 0], [ 101, 2769, 4263, 1266, 776, 1921, 2128, 7305, 102]]), ‘token_type_ids’: tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0]]), ‘attention_mask’: tensor([[1, 1, 1, 1, 1, 1, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1]]), ‘labels’: tensor([[-100, 2769, -100, -100, -100, -100, -100, -100, -100], [-100, -100, -100, -100, -100, -100, -100, -100, -100]])}
DataCollatorForWholeWordMask(DataCollatorForLanguageModeling)
本类集成了上一个类
DataCollatorForLanguageModeling的特性,并多出了全词掩盖的功能。参考
分词介绍
该遮词方法需要在tokenizer分词的时候就对期望连续遮住的词汇的非第一个字前加上##标记.- 原始分词:
‘我喜欢你’–>’我’,’喜’,’欢’,’你’
- wwm形式分词:
‘我喜欢你’–>’我’,’喜’,’##欢’,’你’
- 原始分词:
实操
- 预先准备好哈工大实验室开发的LTP工具,并测试分词
pip install ltpfrom ltp import LTP ltp = LTP() print(ltp.seg(["我爱北京天安门,天安门上太阳升"])[0])[[‘我’, ‘爱’, ‘北京’, ‘天安门’], [‘天安门’, ‘上’, ‘太阳升’]]
下载分词预处理脚本
wget https://raw.githubusercontent.com/huggingface/transformers/v4.10.2/examples/research_projects/mlm_wwm/run_chinese_ref.py引用刚才的脚本,并处理
from run_chinese_ref import prepare_ref from ltp import LTP ltp = LTP() ref = prepare_ref(["我爱北京天安门,天安门上太阳升"], ltp, t) print(ref)[4, 6, 7, 10, 11, 14, 15]
- 表示这些位置的字是全词的子字,即第4个字与第3个字是一个词
北京,第6、7个字与第5个字是一个词天安门,以此类推。
- 遮词
from transformers import BertTokenizer t = BertTokenizer.from_pretrained("hfl/chinese-roberta-wwm-ext") feature = t(["我爱北京天安门,天安门上太阳升"]) # 加上子字信息 feature['chinese_ref'] = ref print(dc(features)){‘input_ids’: tensor([[ 101, 2769, 4263, 1266, 776, 1921, 2128, 7305, 8024, 103, 103, 103, 677, 1922, 7345, 1285, 102]]), ‘labels’: tensor([[-100, -100, -100, -100, -100, -100, -100, -100, -100, 1921, 2128, 7305, -100, -100, -100, -100, -100]])}
- 可知第二个“天安门”词被整个词遮住
DataCollatorForSOP(DataCollatorForLanguageModeling)
- transformers将来版本会被
DataCollatorForLanguageModeling替换,为了避免挖坑,这个类不再介绍
DataCollatorForPermutationLanguageModeling(DataCollatorMixin)
from src.transformers import BertTokenizer, DataCollatorForPermutationLanguageModeling
model_name = 'hfl/chinese-roberta-wwm-ext/'
t = BertTokenizer.from_pretrained(model_name)
dc = DataCollatorForPermutationLanguageModeling(t)
features = [t('我爱哈尔滨,太阳岛真太美了。')]
output = dc(features)
print(output)输出特征有
input_ids:
tensor([[ 101, 103, 103, 103, 2209, 4012, 103, 103, 7345, 2270, 103, 1922, 5401, 749, 511, 102]])perm_mask:
tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 1., 0., 0., 0., 0., 1., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 1., 1., 1., 0., 0., 1., 1., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 1., 0., 1., 0., 0., 1., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 1., 1., 1., 0., 0., 1., 1., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 1., 1., 1., 0., 0., 1., 1., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 1., 0., 1., 0., 0., 1., 1., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 1., 1., 1., 0., 0., 1., 1., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 1., 1., 1., 0., 0., 1., 1., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 1., 1., 1., 0., 0., 1., 1., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 1., 1., 1., 0., 0., 1., 1., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 1., 1., 1., 0., 0., 1., 1., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 1., 1., 1., 0., 0., 1., 1., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])target_mapping
tensor([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]])labels
tensor([[-100, 2769, 4263, 1506, -100, -100, 8024, 1922, -100, -100, 4696, -100, -100, -100, -100, -100]])}
直接看输出有点晕,先看labels
观察发现第1、2、3、6、7、10位置(位置从左到右,从0开始数)的值是非0的,根据上面的分析,已经知道这些是遮挡的词,参与计算损失函数的
把perm_mask画成热力图如下图所示: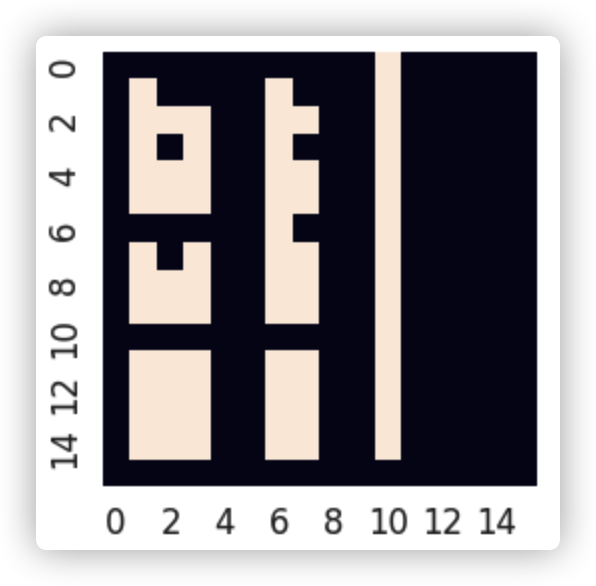
- 第10行,白色只有第10列,表示第10个字只能看到它自己
- 第6行,白色有第6列,第10列,表示第6个字能看到第10个字
- 以此类推
p(x10)
p(x6|x10)
p(x1|x6, x10)
p(x3|x1, x6, x10)
p(x7|x1, x3, x6, x10)
p(x2|x1, x3, x6, x7, x10)


