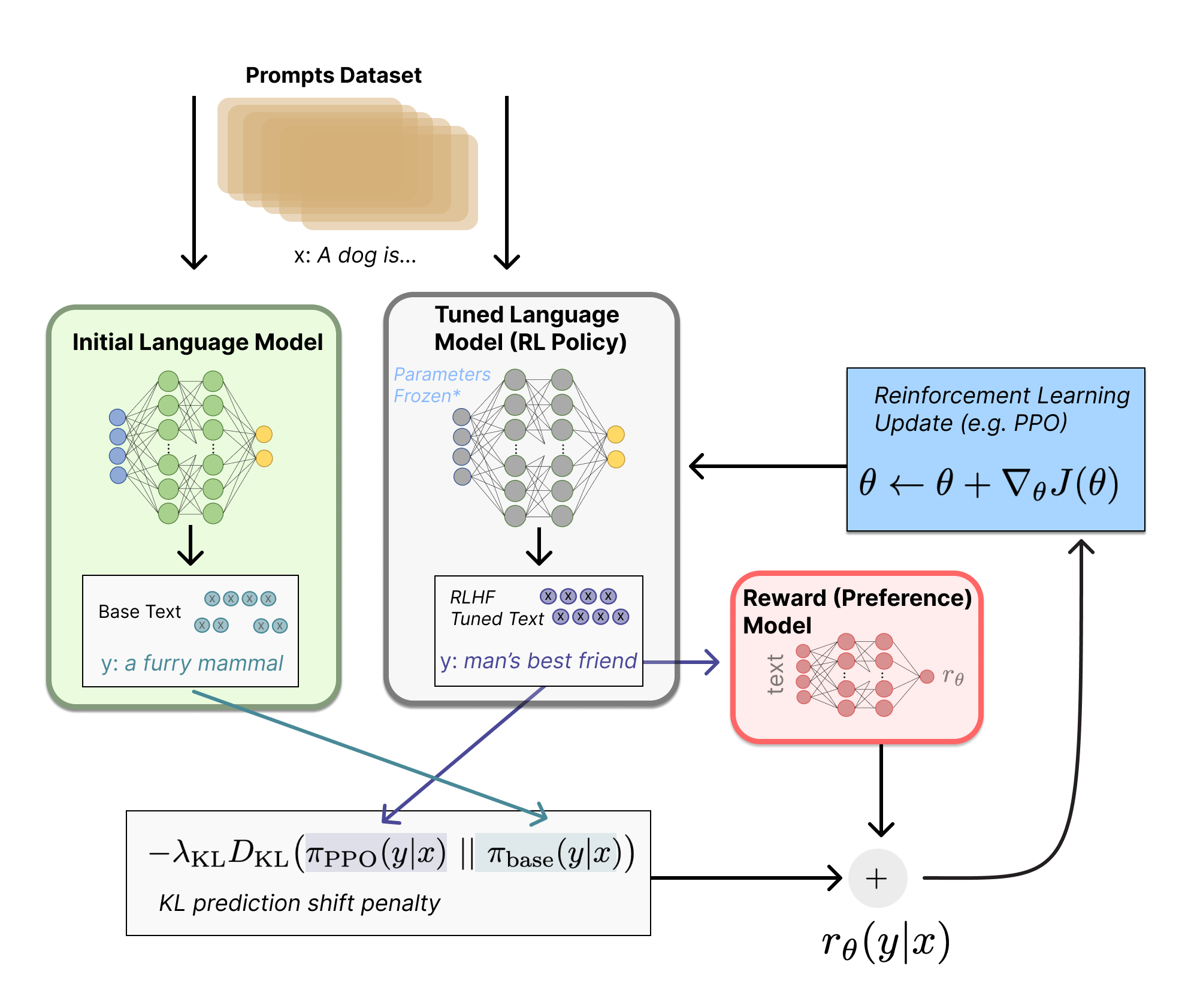
摘要
最近几个月开源的Stable Diffusion模型是一个非常棒的模型,它在图像生成领域有着现象级的表现。网上已经有分享大量关于它的画质精美的生成图像。但这个模型是有着10亿级别的参数量,5.2GB的内存占用,一般的家用显卡很难运行起来。因此,这篇博客探索了使用OnnxRuntime工具对模型进行了量化压缩,在CPU硬件上将50个生成step推断速度从torch版本7分钟降低到量化版本4分钟,同时将模型大小从5.2GB降低到1.3GB,于此同时保证了高质量的图片生成效果。为了便于使用,在这里又使用了Streamlit工具对模型进行包装,可以方便的在页面对生成参数进行调整和图片生成。同时Streamlit也支持实时显示扩散模型运行进度,支持画廊查看历史生成结果。最后把以上的量化过程、必要的python环境、Streamlit服务,都通过Github Action打包成镜像,使用者仅需要一个docker-compose.yaml的配置,就可以直接在本地CPU上私有化部署起来。以上源码都已开源,欢迎大家参考使用。
关键词解释
- Streamlit:
- 一个流行的开源框架,可以快速搭建机器学习和数据科学团队的Web应用。
- CompVis/stable-diffusion-v1-4:
- 一个流行的扩散模型,可以通过文字提示生成栩栩如生的高质量图片。
- OnnxRuntime:
- 微软推出的一款推理框架,用户可以非常便利的量化压缩模型。
私有化部署方法
- 安装docker、docker-compose
- 复制下面的docker-compose.yml
version: "2.3" services: stable-diffusion-streamlit-onnxquantized: container_name: stable-diffusion-streamlit-onnxquantized image: lowinli98/stable-diffusion-streamlit-onnxquantized:v0.2 expose: - 8501 ports: - "8501:8501" environment: - APP_TITLE=Stable Diffusion Streamlit restart: always volumes: - /etc/localtime:/etc/localtime - ./volume:/app/pages/model/result
- 复制下面的docker-compose.yml
- 拉取镜像和运行
docker-compose up -d
- 拉取镜像和运行
使用效果
- 修改运行参数, 粘贴提示,点击”开始生成”。
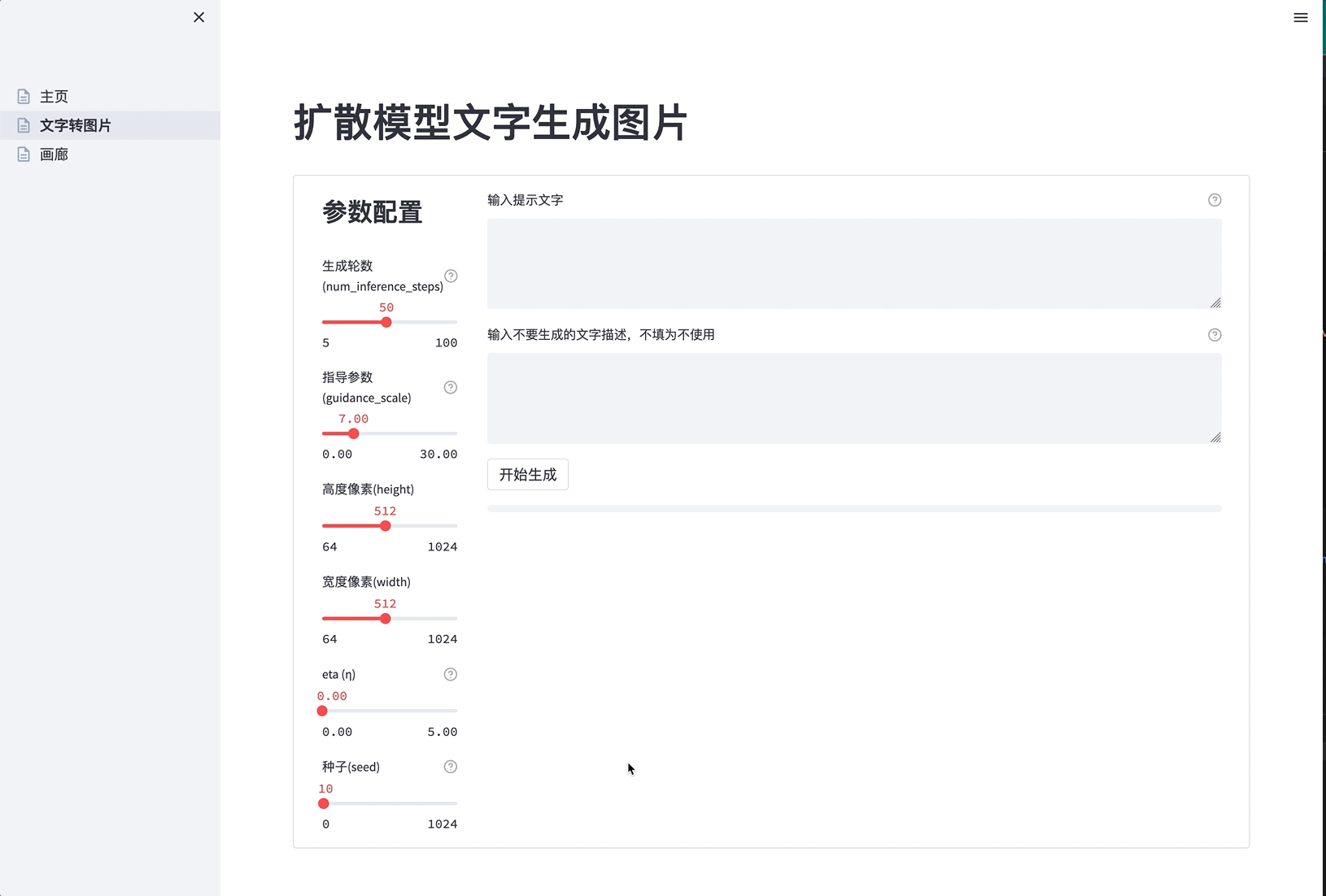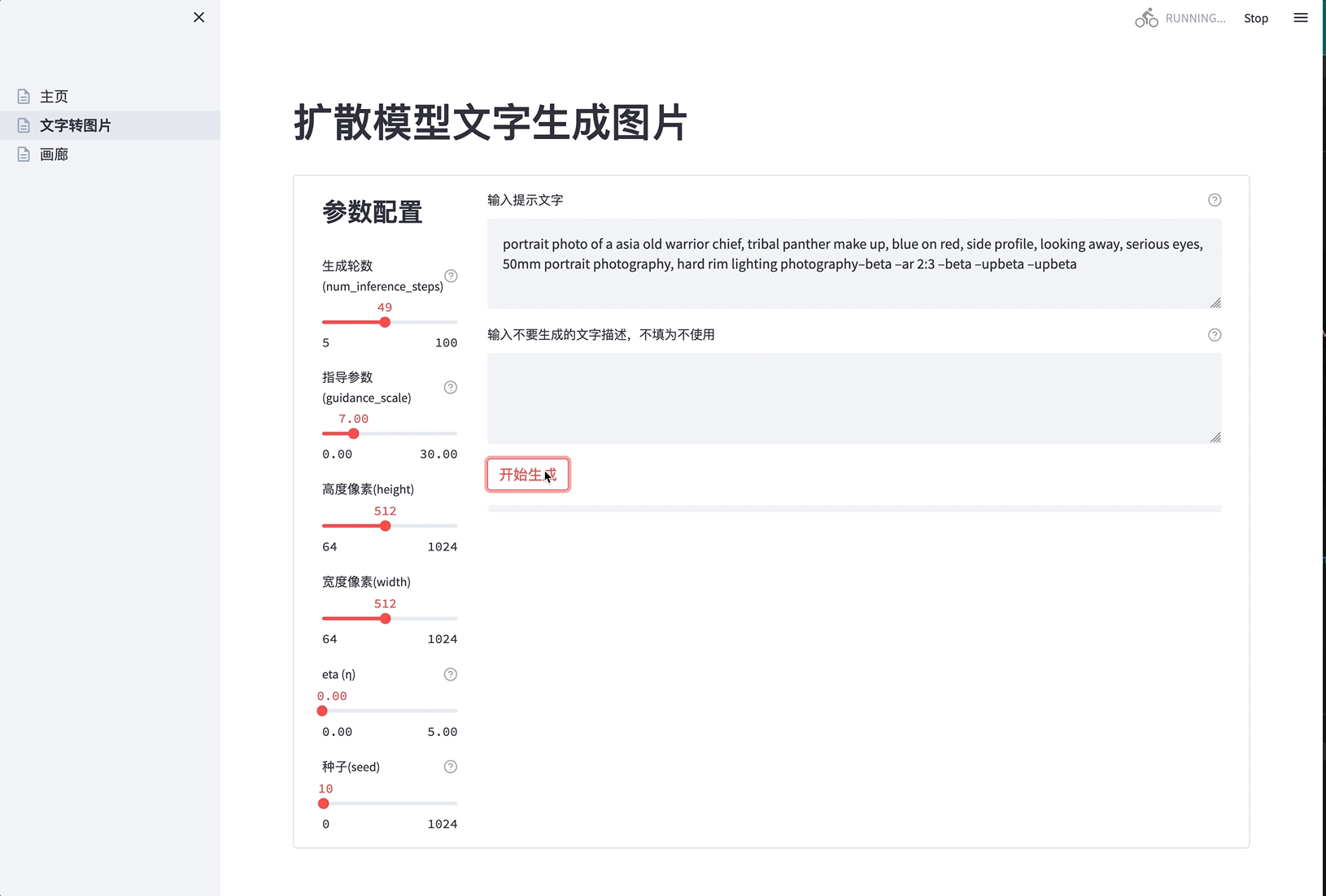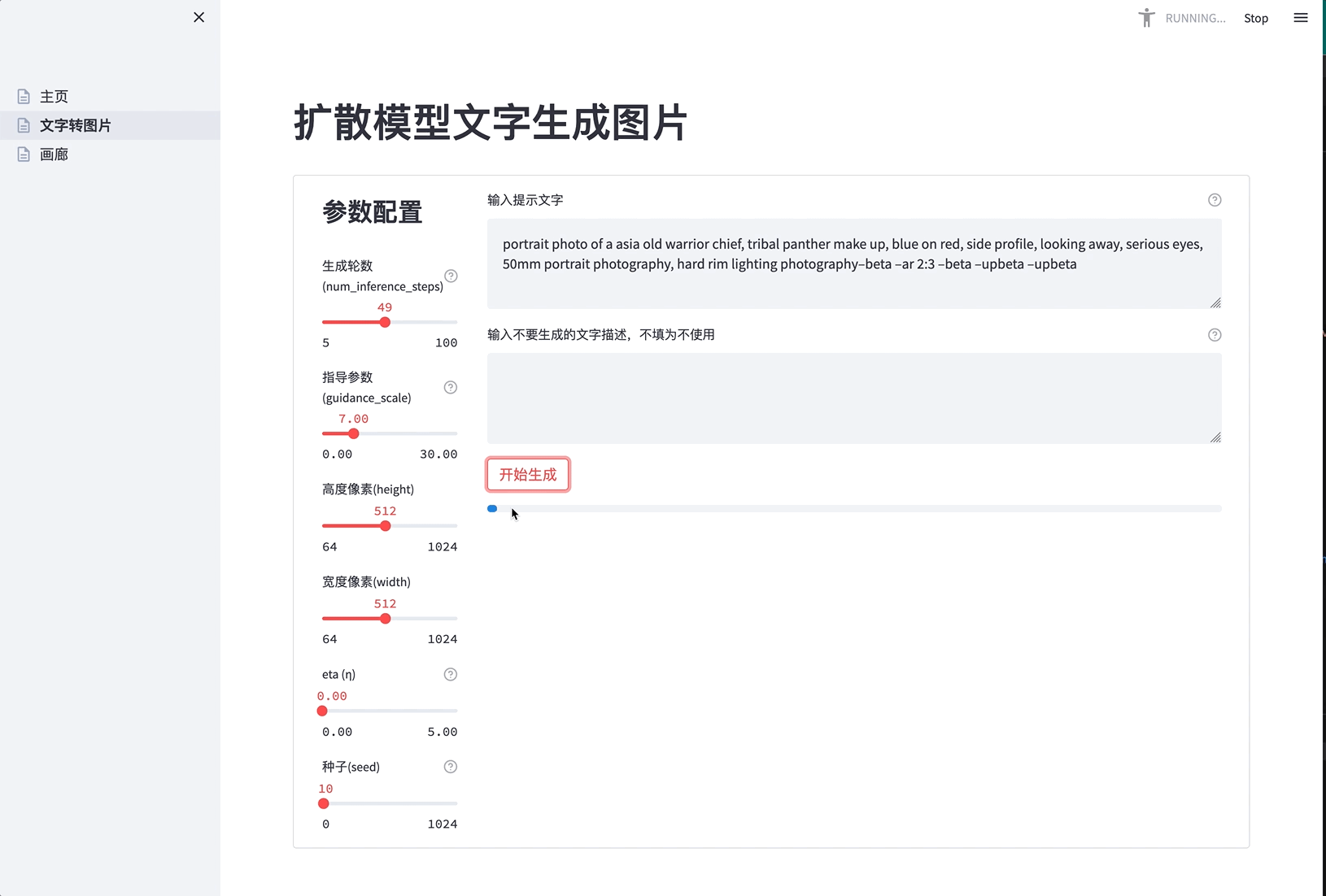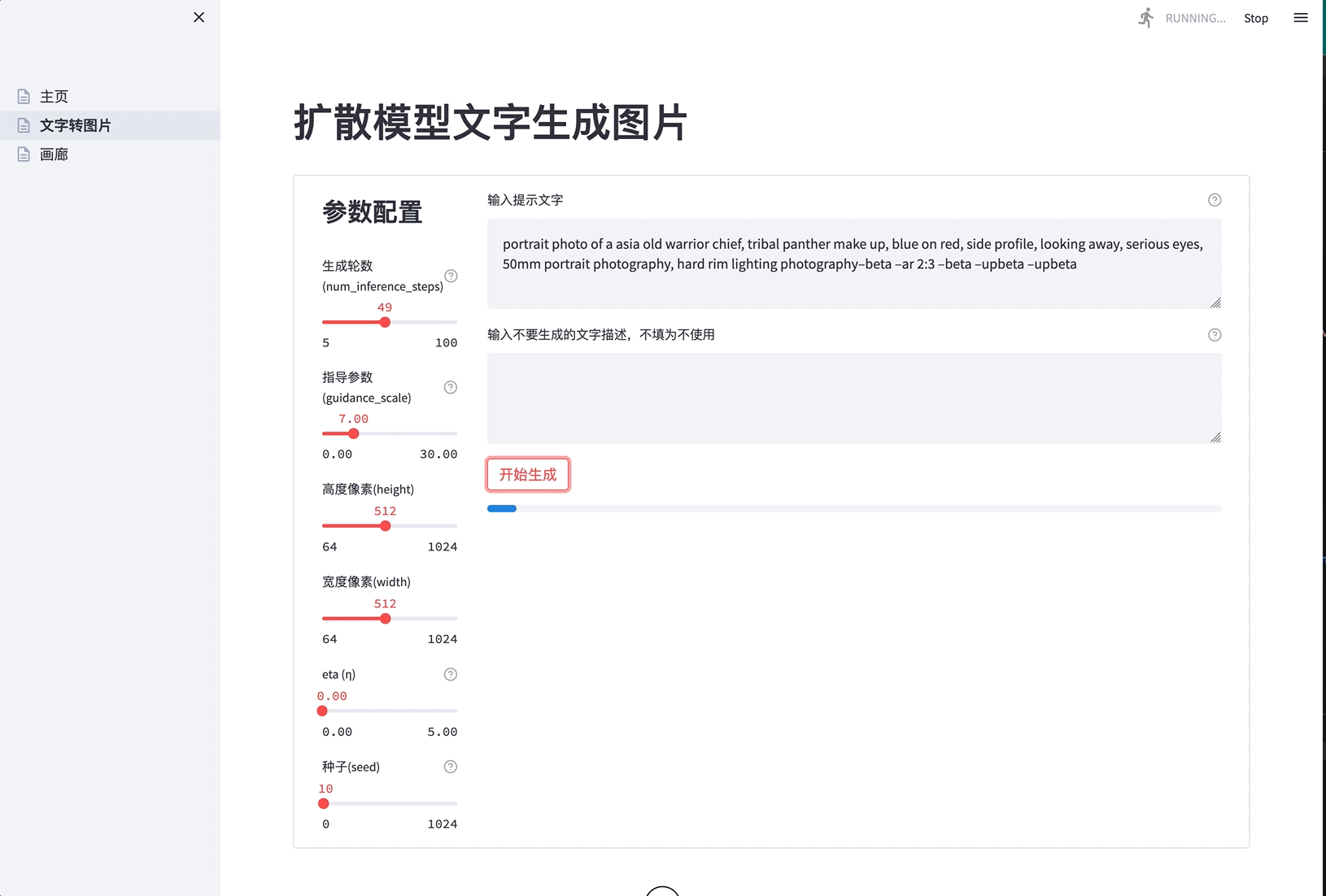
- 修改运行参数, 粘贴提示,点击”开始生成”。
- 待进度条走完后,页面直接展示生成的图片
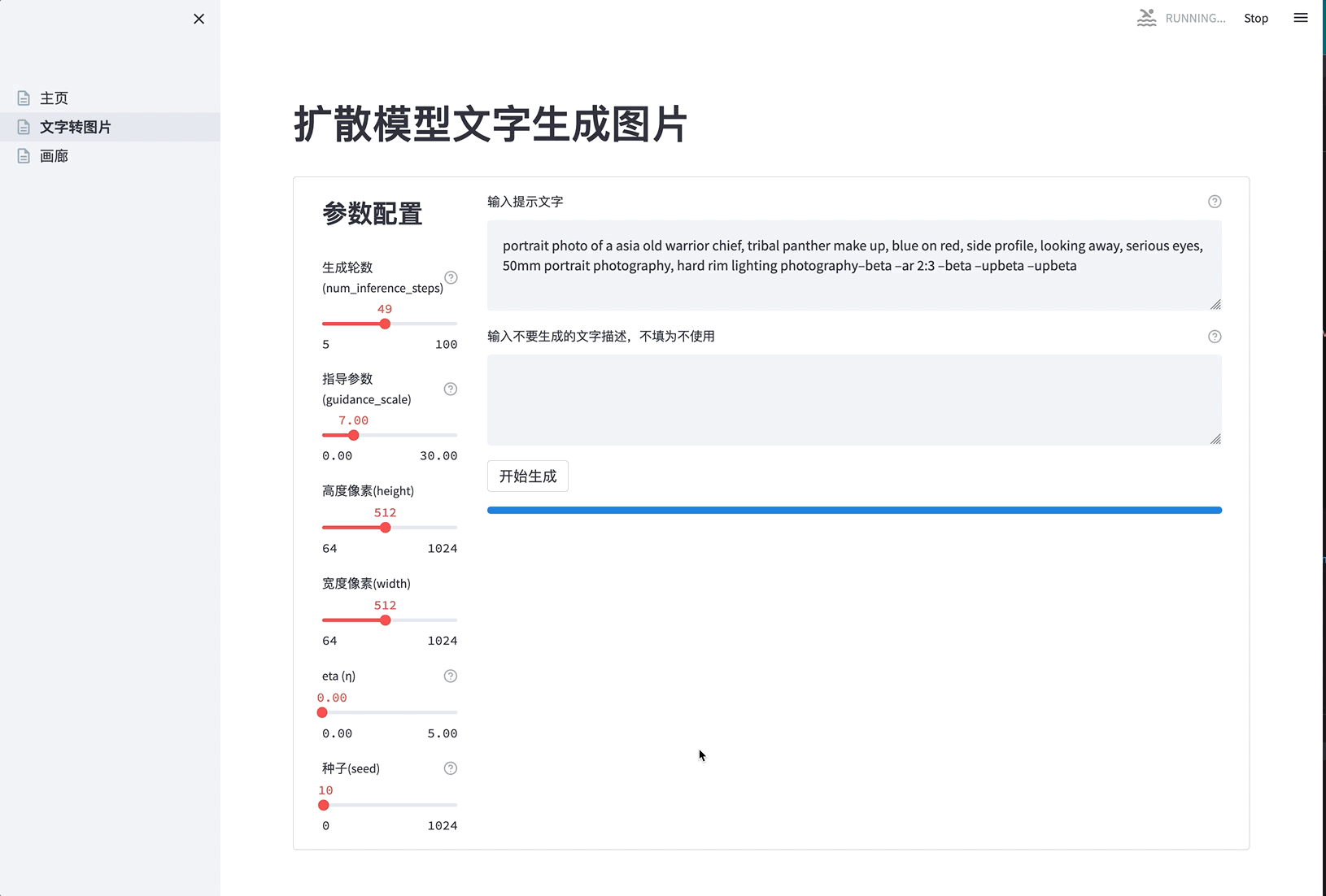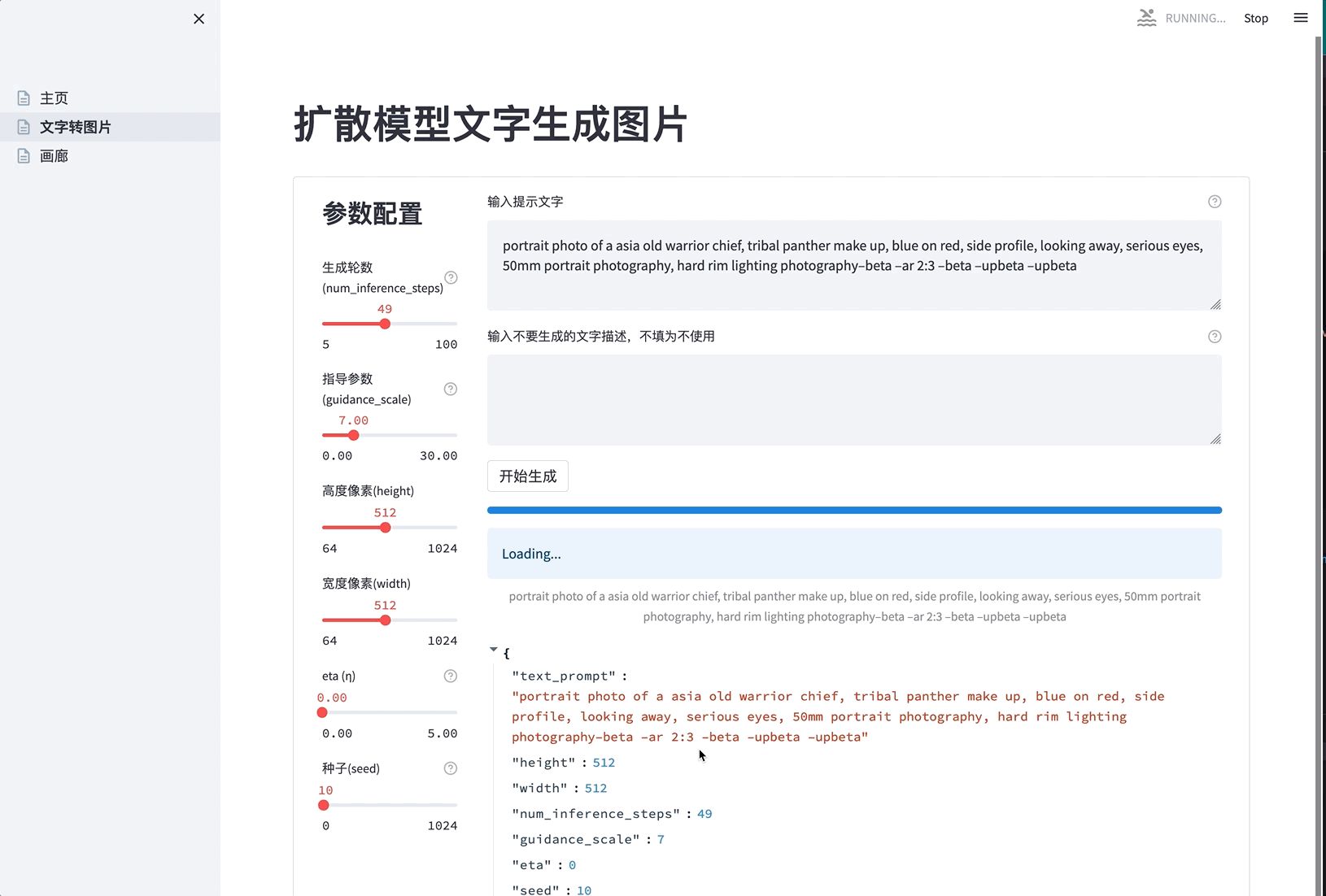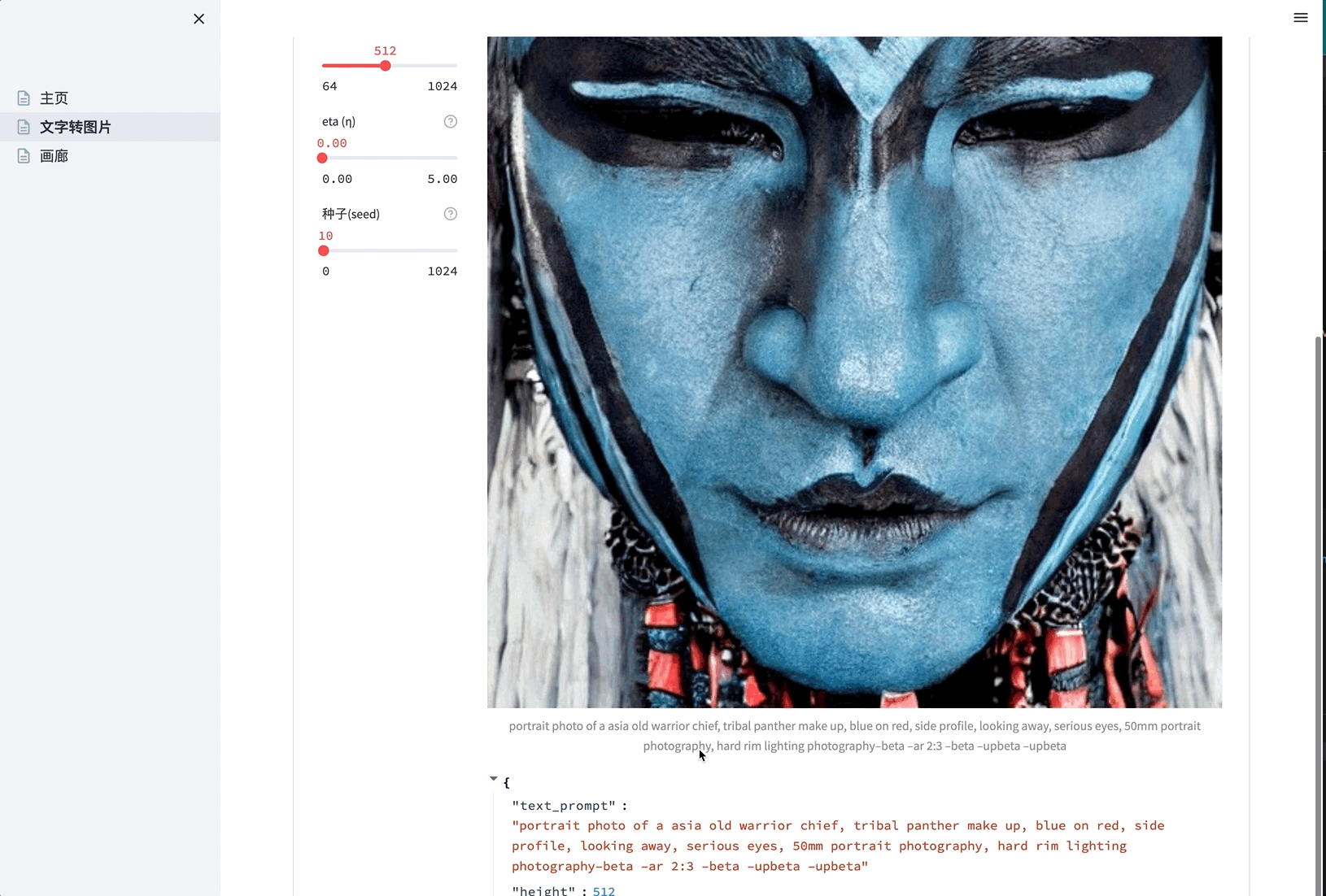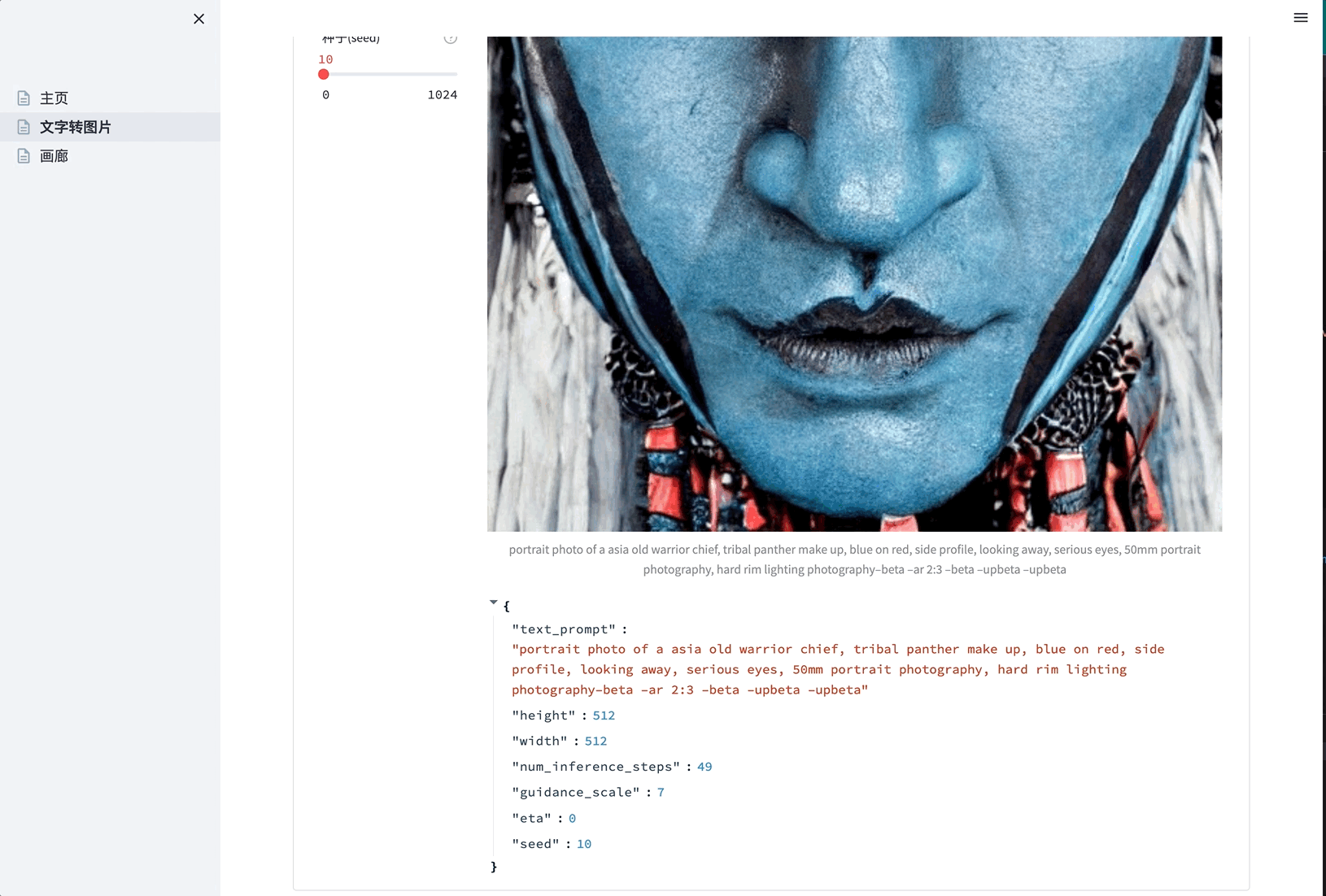
- 待进度条走完后,页面直接展示生成的图片
- 点击侧边栏的”画廊”查看所有历史生成的图片
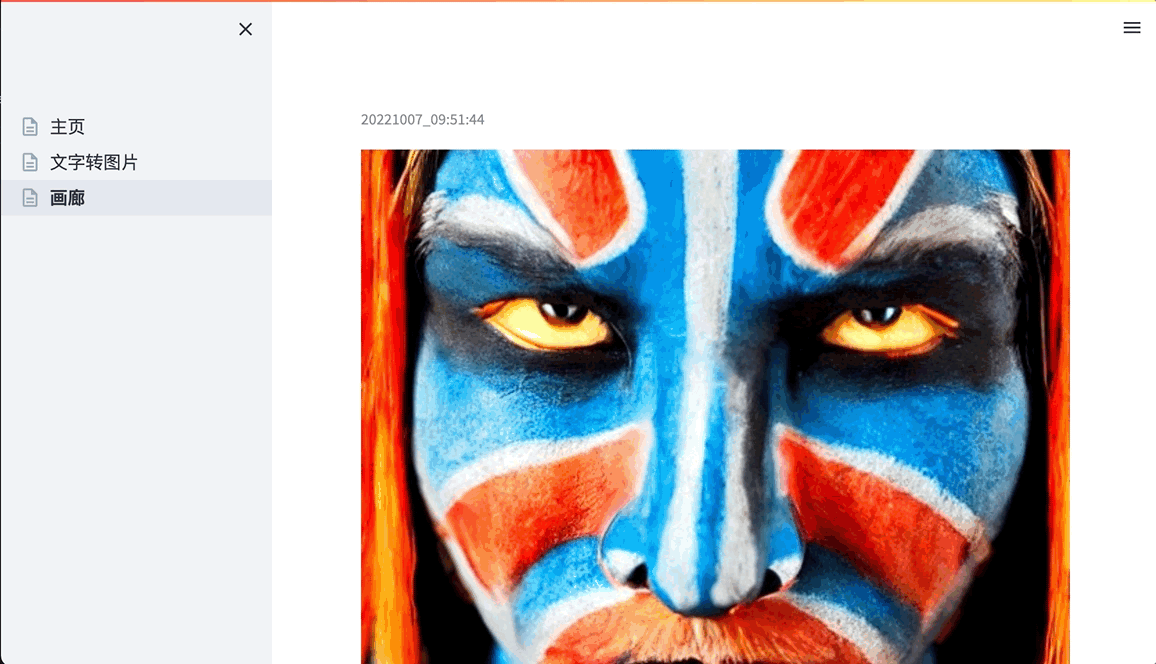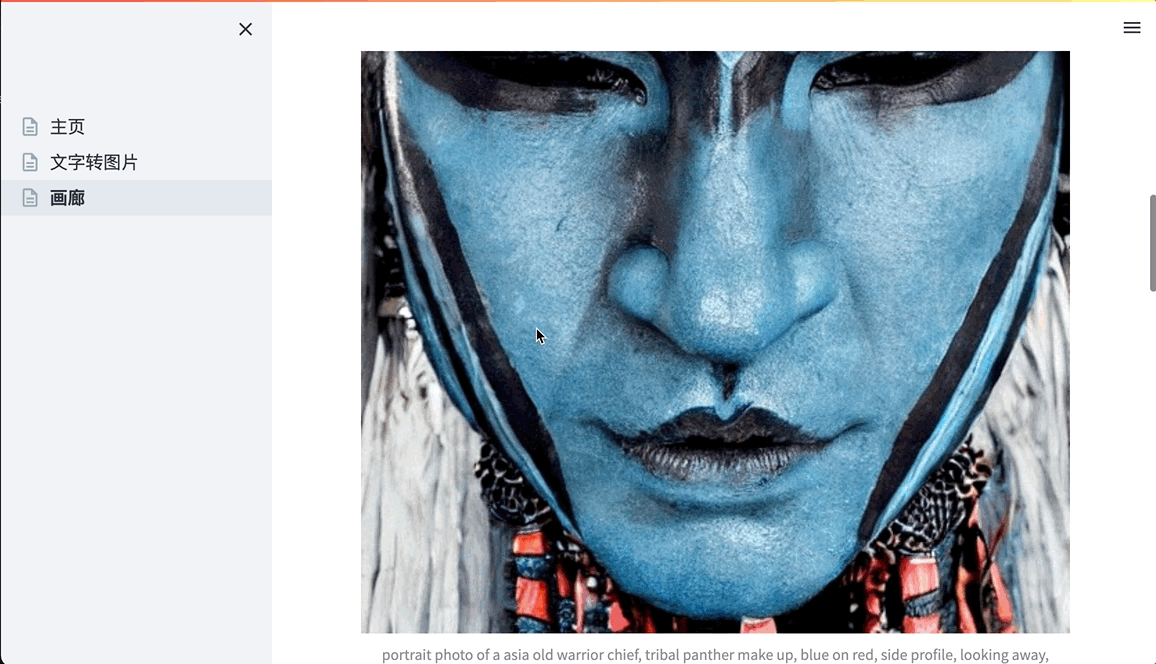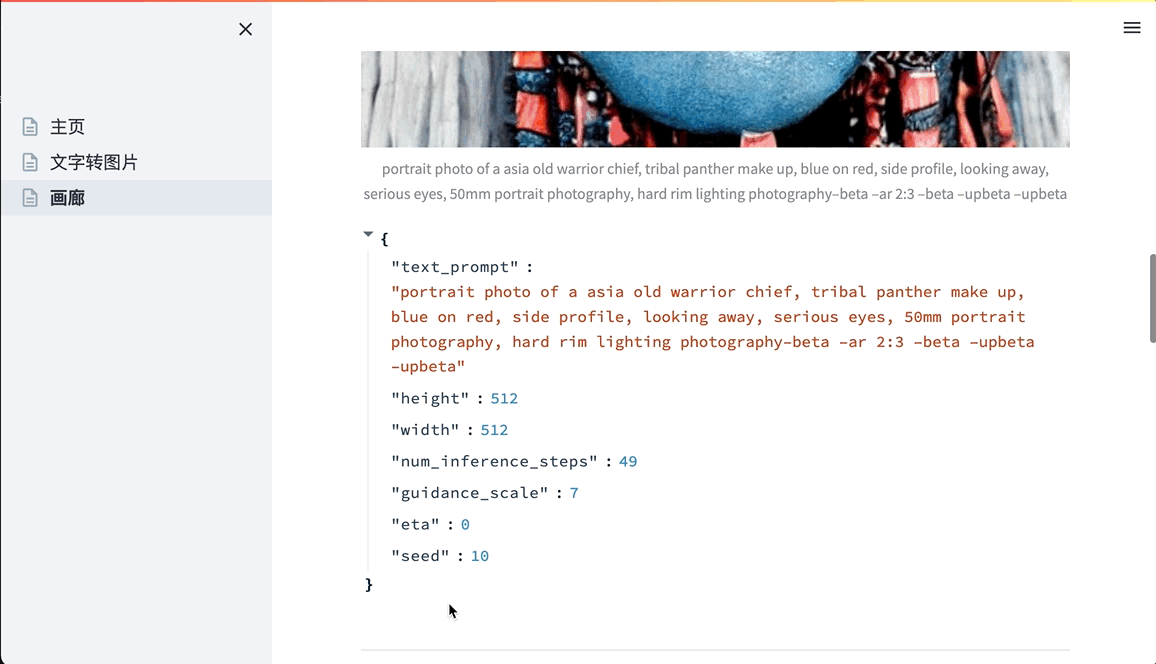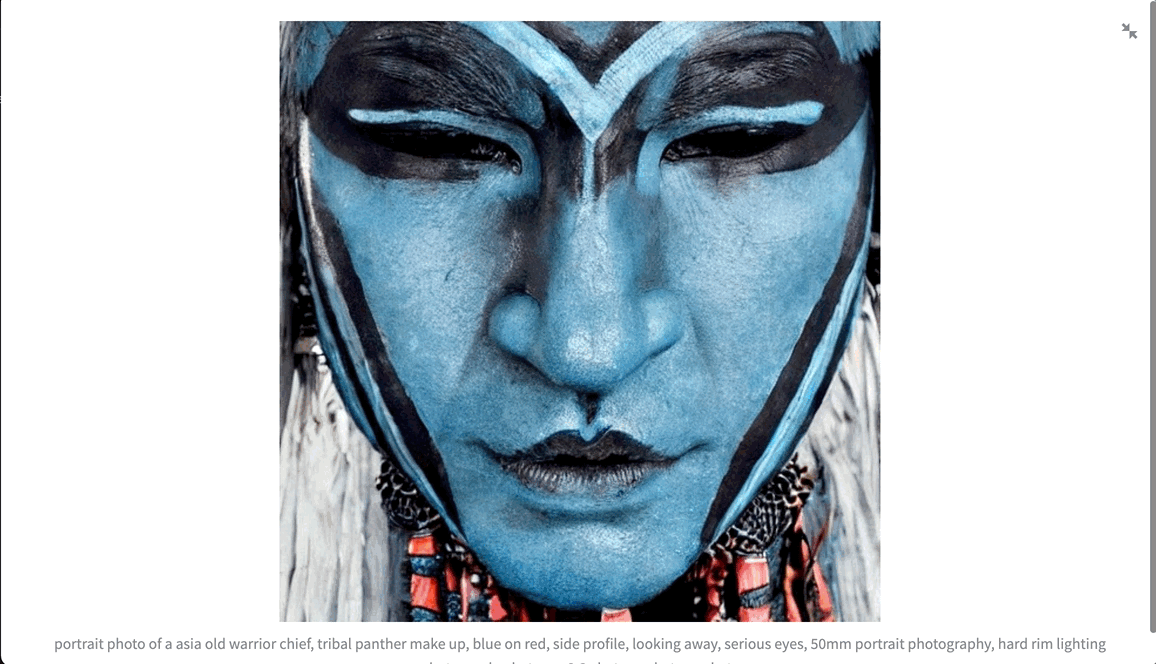
- 点击侧边栏的”画廊”查看所有历史生成的图片
模型量化对比
- CompVis/stable-diffusion-v1-4
| 模型格式 | 空间占用 | 推断50个step用时(minutes) |
|---|---|---|
| pytorch | 5.2GB | 7分47秒 |
| onnx | 5.0GB | 4分34秒 |
| onnx-quantized(QUINT8) | 1.3GB | 4分29秒 |
cpu:
- Intel(R) Xeon(R) CPU E5-2650 v3 @ 2.30GHz
- 10 core
PyTorch模型生成的图片

Onnx模型生成的图片

Onnx-quantized(UINT8)模型生成的图片

研究记录
1. 准备python环境
安装python
安装依赖
pip install torch==1.10.0 transformers==4.22.2 onnx==1.12.0 onnxruntime==1.12.1 diffusers==0.4.0 streamlit==1.13.0 ftfy==6.1.12.下载模型
CreativeML OpenRAIL License
如果是第一次下载模型,需要额外确认License,该License尤其指出不得使用生成的图像作为非法用途、生成的图像权利归用户而不是模型提供方。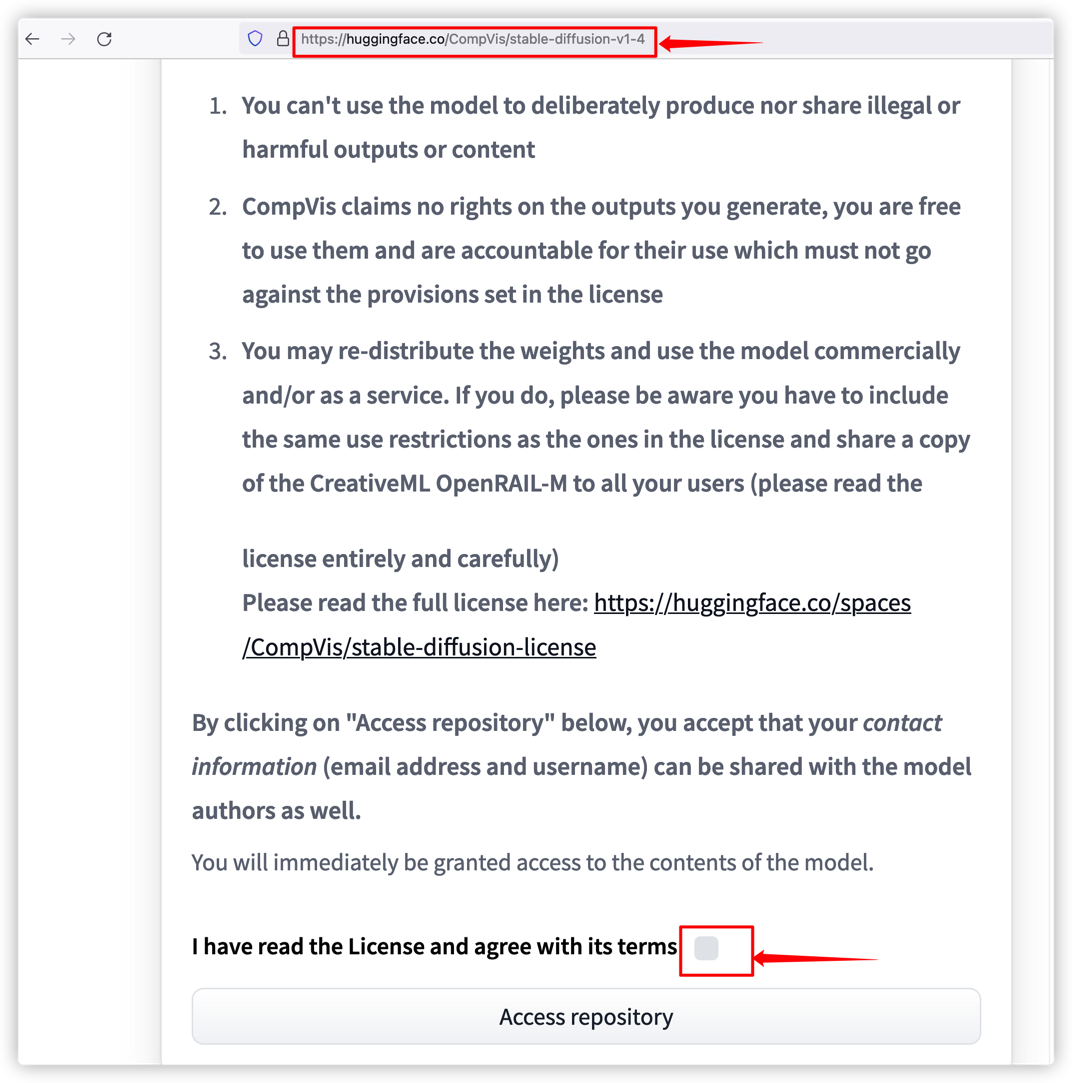
Huggingface ModelHub上已经支持直接下载Onnx格式模型,参考官网文档输入
from diffusers import StableDiffusionOnnxPipeline pipe = StableDiffusionOnnxPipeline.from_pretrained( "CompVis/stable-diffusion-v1-4", revision="onnx", provider="CPUExecutionProvider", )输出报错
OSError: Token is required (`use_auth_token=True`), but no token found. You need to provide a token or be logged in to Hugging Face with `huggingface-cli login` or `notebook_login`. See https://huggingface.co/settings/tokens.
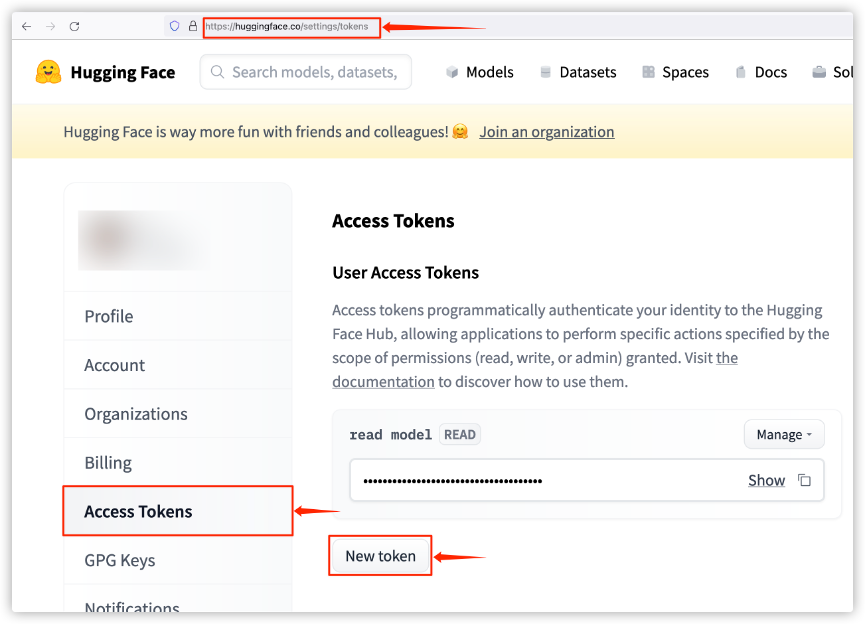
原来这个模型必须要通过token登录才能下载,也即确认过License的用户才可以下载。在Huggingface官网登录,然后生成token
- 输入
from diffusers import StableDiffusionOnnxPipeline pipe = StableDiffusionOnnxPipeline.from_pretrained( "CompVis/stable-diffusion-v1-4", revision="onnx", provider="CPUExecutionProvider", use_auth_token="******" # 换成自己的token ) - 经过近5GB+的模型文件下载,得到包装了多个模型的pipe对象
- 模型另存至本地
pipe.save_pretrained("./onnx") - 输出报错
FileNotFoundError: [Errno 2] No such file or directory: './onnx/vae_decoder/model.onnx' - 检查diffusers源码,发现在另存的函数中,检查另存目录模型是否和缓存的模型一致,若不一致就另存覆盖。但是如果另存目录没有文件时,就会报错。该bug已经提交pull request给Huggingface官方,等待修复合并。
- 临时解决方案,手动创建目录和空的模型文件,再另存,详见下面代码块或项目源码
import os
for tmp_dir in ["safety_checker", "text_encoder", "unet", "vae_decoder"]:
os.makedirs(os.path.join("./onnx", tmp_dir), exist_ok=True)
with open(os.path.join("./onnx", tmp_dir, "model.onnx"), "wb") as f:
f.write(b"")
pipe.save_pretrained("./onnx")- 另存结束后,读取尝试
StableDiffusionOnnxPipeline.from_pretrained("./onnx") - 又报了一大串错误,最后一行为:
RuntimeException: [ONNXRuntimeError] : 6 : RUNTIME_EXCEPTION : Exception during initialization: /onnxruntime_src/onnxruntime/core/optimizer/initializer.h:149 onnxruntime::Initializer::Initializer(const onnx::TensorProto&, const onnxruntime::Path&) status.IsOK() was false. ReadExternalRawData() failed: open file "./onnx/unet/weights.pb" failed: No such file or directory unet/weights.pb是什么鬼?onnx的模型不都是以后缀名.onnx的吗?为什么会缺失一个.pb的文件?进入该目录后发现,确实没有该文件,只有一个764K的model.onnx。然后查看整个./onnx目录,发现只有1.8GB,pipe下载的时候不是有5GB+吗?- 带着怀疑的态度,进入Huggingface的模型缓存目录查看,一般默认缓存目录在
~/.cache/huggingface/下,在这里搜索一下weights.pb:cd ~/.cache/huggingface find -name "weights.pb" - 果然找到了
weights.pb,然后咱们把它复制到./onnx/unet/目录下。Okay,另外3.5GB的模型权重补上了。再次读取尝试StableDiffusionOnnxPipeline.from_pretrained("./onnx") - 终于读取成功了。但是为什么会存在这样一个文件呢?好在Huggingface官方提供了模型转ONNX的脚本,我们可以看看是怎么操作转换的ONNX。然后我看到了这里的注释:
use_external_data_format=True, # UNet is > 2GB, so the weights need to be split - 原来是因为
unet模型太大,需要使用参数use_external_data_format=True来分割模型,生成了一个新的文件weights.pb。但是在StableDiffusionOnnxPipeline的save_pretrained函数中,并没有另存这份文件。好吧,那只能临时手动复制一份weights.pb到./onnx/unet/目录下。详见项目源码
3.OnnxRuntime量化
关于量化技术是什么,建议博主的另一篇博客
OnnxRuntime的量化接口是
quantize_dynamic,详见官方文档。一个pipe是会存多个模型的,我们要对每一个model.onnx都进行量化操作,如下所示:import os from onnxruntime.quantization import quantize_dynamic for root, dirs, filenames in os.walk("./onnx"): if "model.onnx" in filenames: quantize_dynamic( model_input=os.path.join(root, "model.onnx"), model_output=os.path.join(root, "model.onnx"), # 量化后的onnx模型文件覆盖原onnx模型文件 per_channel=True, reduce_range=True, optimize_model=True, ) print("Quantized model saved at: ", os.path.join(root, "model.onnx"))激动人心的时刻来了,我们把每个model量化后的pipe再次加载起来,并开始运行
quant_pipe = StableDiffusionOnnxPipeline.from_pretrained( "./onnx", provider="CPUExecutionProvider", local_files_only=True ) quant_pipe("Hello world!")又报错了:
onnxruntime.capi.onnxruntime_pybind11_state.NotImplemented: [ONNXRuntimeError] : 9 : NOT_IMPLEMENTED : Could not find an implementation for ConvInteger(10) node with name 'Conv_167_quant'这个错误日志看起来是因为
ConvInteger这个op在onnxruntime中还没有找到,我们去OnnxRuntime的GitHub去搜一下Issue,详见这里,在这里找到了一个Issue找到一些线索。有一个高赞的回答是把参数weight_type默认取值QInt8改为QUInt8,但是下面也有回答说QUInt8的推断速度是比Qint8的速度更慢的。那么UINT8和INT8的区别是什么呢?看一下官方文档的解释。这里它们的区别字符”U”表示unsigned,看起来一个量化后取值范围是否包含正负号的区别,官方文档提到模型的权重分为activations和weights两种,推荐首选都是用QInt8格式,量化压缩的损失最少。刚才那个Issue里也测试了量化不同算子的效果,但是那个方法也没有很清晰。所以在这里就都统一用QUInt8格式继续试验了。修改量化脚本为
import os from onnxruntime.quantization import quantize_dynamic for root, dirs, filenames in os.walk("./onnx"): if "model.onnx" in filenames: quantize_dynamic( model_input=os.path.join(root, "model.onnx"), model_output=os.path.join(root, "model.onnx"), # 量化后的onnx模型文件覆盖原onnx模型文件 per_channel=True, reduce_range=True, optimize_model=True, weight_type=QuantType.QUInt8, # <---新加这里1 ) print("Quantized model saved at: ", os.path.join(root, "model.onnx")) if "weights.pb" in filenames: os.remove(os.path.join(root, "weights.pb")) # <---新加这里2,删掉量化前的大文件 print("Removed weights.pb")然而现在在量化过程,还会有很多Warning,如下所示:
Ignore MatMul due to non constant B: /[MatMul_819] Ignore MatMul due to non constant B: /[MatMul_982] ...最后我们再次调用一次推断
quant_pipe = StableDiffusionOnnxPipeline.from_pretrained( "./onnx", provider="CPUExecutionProvider", local_files_only=True ) result = quant_pipe("Hello world!")终于成功了!!!
4. Streamlit包装服务
- 以上还只是在代码里跑模型,我们还需要把模型包装成一个web服务,让任何不会写代码的人都可以在线调试模型,感受它的魅力。
- 这里使用Streamlit来实现,Streamlit是一个开源的Python库,可以用来快速构建和部署数据应用程序。它的核心是一个Python库,可以让你在几分钟内创建一个数据应用程序,而无需编写任何HTML或JavaScript。
- 闲话少说,根据官方文档,把各种模型推断参数包装到streamlit.slider里,供页面调试修改,并在提交按钮后调用模型推断。
progress进度条
- 这时发现了一个问题,为了生成高质量图片,扩散模型一般要推断很多步(默认50步),这会比较耗时,即使量化后的模型也要接近5分钟。为了提升用户体验,在页面做了一个进度条streamlit.progress,然后把模型推断放在单独的一个线程里,用另一个线程,监控
quant_pipe的推断步数,并更新到进度条中。详见项目源码。pipeline改无状态
- 又发现了一个很重要的问题,这个streamlit页面如果有两个用户同时进行推断计算时,会抛异常,因为
quant_pipe是全局变量模型,而quant_pipe.scheduler是一个有状态的对象,它会记录扩散模型每个step的计算结果。因此它不能被页面触发的多个线程同时访问。为了解决这个问题,在每次线程启动quant_pipe计算时,在线程里把quant_pipe.scheduler单独复制一份。这样每个线程就有自己独立的quant_pipe.scheduler了,线程之间就不会互相干扰了,而其他model部分是通用的,以便节省内存资源。详见项目源码画廊👀
- 好了,我们现在可以线上调试生成模型了,但目前还都是要自己保存算了半天的图片、自己记录生成参数,这实在太不方便了。那么咱直接在服务里,把每次生成的图片、生成的参数按照固定方式存起来即可。然后在画廊里,遍历查看所有历史结果岂不美滋滋。详见项目源码。
5.打包成docker镜像
- 为了方便部署,以上模型下载、模型量化、streamlit服务,统一在项目Actions中打包成docker镜像,并发布了DockerHub,那么我们部署时就是开箱即用,docker-compose.yaml跑起来既可,详见博客开头私有化部署方法。把模型加载起来,docker服务仅占用了2GB内存,跑起来模型仅占用了不到8个GB内存,个人觉得还是挺给力的。
计划
- 通过Huggingface/Diffusers还可以做很多好玩的事情,比如通过一段文字提示,用图片生成新图片Text-Guided Image-to-Image、用文字提示,遮图生成新图片https://huggingface.co/docs/diffusers/using-diffusers/inpaint。Huggingface的官方介绍博客在这里。
- 本来是想把这些功能都做到项目里,但是Diffusers目前(0.4.1)官方还只支持文字生成图片的Onnx Pipeline,需要额外自己动手改写其他Pipeline的Onnx支持。但好在这似乎也并不麻烦,详见Issue。
- 所以后续计划是加入更多好玩OnnxRuntime量化后的Pipeline,继续丰富功能。