原博客
完整notebook代码
![]()
训练或是微调SentenceTransformer模型,主要取决于有什么样的数据,做什么样的任务。
- 输入模型的数据如何处理
- 不同损失函数与数据集的关系
在这篇博客里,我们可以:
- 学会如何从零创建一个
SentenceTransformer模型,或使用HuggingFace社区的模型进行微调; - 了解做句子编码模型的几种数据集格式;
- 基于数据集格式,回顾几种可选的损失函数;
- 训练或微调模型
- 在HuggingFace社区分享模型
- 句子编码模型的适用范围
句子编码模型的工作方式
在SentenceTransformer模型中,它将不同长度的文本(或图像像素)转换成固定长度的嵌入向量,它代表了输入的语义。嵌入向量的介绍详见另一篇博客。本篇博客聚焦与文本本身。
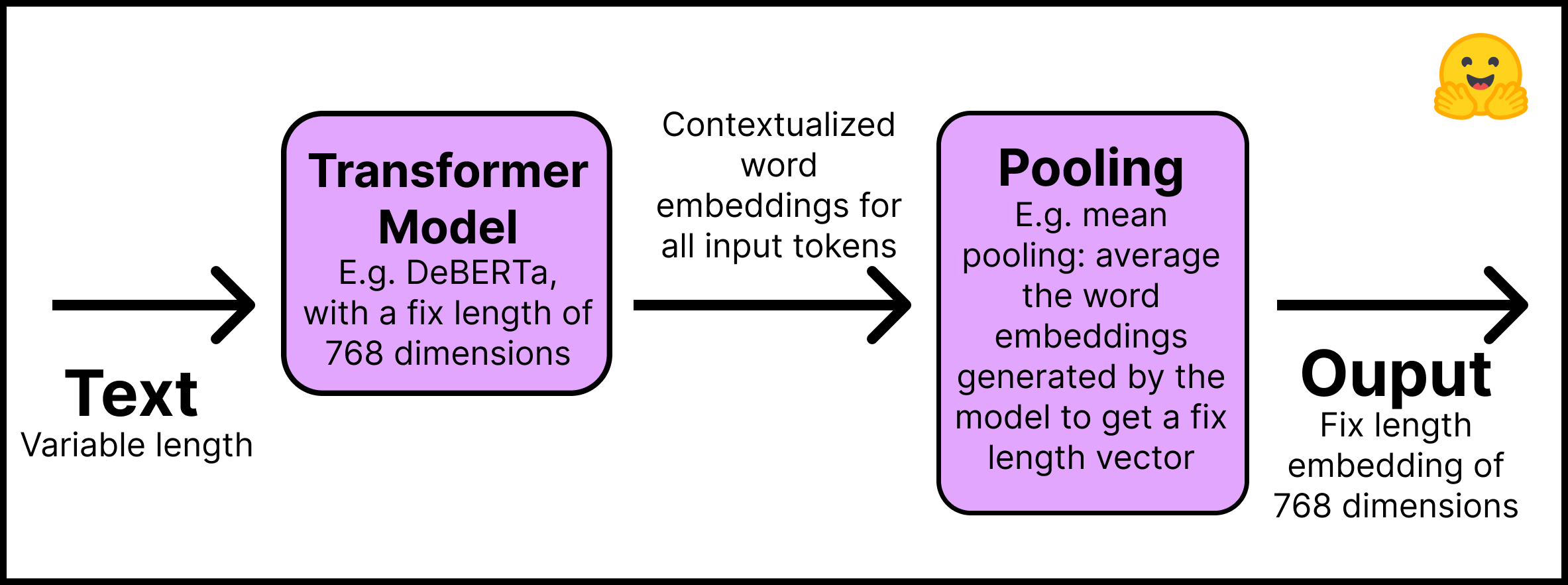
- 下面是句子编码模型的运行方式
- 第一层 文本输入至Huggingface社区的预训练Transformers模型,本篇博客使用的Distilroberta-base模型。输出每个输入词对应位置的编码向量。
- 第二层 编码向量输入至池化层,获得一个固定长度的编码向量。例如,池化层可以是所有词编码向量的平均值。
如下图所示
- 安装
sentence-transformers
pip install -U sentence-transformers- 运行
from sentence_transformers import SentenceTransformer, models
## 第一步:选择一个已有语言模型
word_embedding_model = models.Transformer('distilroberta-base')
## 第二步:使用一个池化层
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension())
## 将前两步合在一起
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
通过以上的代码,可以将两步合在一起,在模型中一起执行。第一层输入文本,最外层输出句子编码向量。以上就是句子编码模型的典型架构,如果需要,还可以加入其他层,如全连接层、卷积层等。
为什么不直接使用transformer模型呢,如BERT或Roberta,直接跑出所有编码向量,以下有两个原因:
- 预训练transformers模型跑语义搜索任务需要很重的计算量。例如,从10000个句子中寻找最相似的句子对需要5千万次推断,对于BERT模型来说需要跑65个小时。相反,使用SentenceTransformers的BERT模型,可以减少到接近5秒。
- transformers模型的句子表示效果并不好。是用BERT模型的向量池化平均值甚至不如2014年的GloVe编码
在本节中,我们从零开始创建一个SentenceTransformers模型。如果只想关心模型的微调,可以跳过上面的步骤,直接从Huggingface社区导入。社区中SentenceTransformers模型大多是通过句子相似度任务得到的。下面是载入的sentence-transformers/all-MiniLM-L6-v2模型。
from sentence_transformers import SentenceTransformer
model_id = "sentence-transformers/all-MiniLM-L6-v2"
model = SentenceTransformer(model_id)
接下来是最重要的部分:数据格式
如何准备训练SentenceTransformers模型的数据集
首先需要知道句子之间的相似度。因此,每条数据需要一个标签,让模型知道每对句子是相似还是不同。
遗憾的是,并没有统一的方法准备数据。因为这取决于你的目标和你已有的数据的结构。如果你没有上面预想的这种描述句子相似程度的标签,你就需要依靠每个句子所在文档位置的信息来设计策略自动获取标签。例如,来源于同一篇文档的两个句子,比不同文档的两个句子语义更接近。相邻的句子比不相邻的句子更接近。
数据结构也会影响到我们要选择的损失函数。在下一节讨论。
记得博客开头的notebook中有所有实验的源码
大多数数据可以遵循以下四种格式之一。
- 一条数据包含一对句子和一个描述它们相似的标签,标签可以是整数也可以是小数。这种格式源于
Natural Language Inference (NLI),NLI任务是给定一对句子,判断它们是否相关。 - 一条数据包含相似的句子对,没有标签。例如,同一句话的一对不同解释、原文摘要对、重复的问题、重复的回复。NLI数据集也可以做成这种数据格式。对于这种数据格式,可以用
MultipleNegativesRankingLoss损失函数,它是一种SentenceTransformers最常见的损失函数。 - 一条数据包含一个句子和一个代表句子所属类别的整数标签。这种数据格式很容易转换成三个句子的组合,第一个句子是基准,第二个句子是代表和基准属于一个类别的正样本、第三个句子是代表和基准不属于一个类别的负样本。
- 一条数据包含三个句子(基准、正样本、负样本),没有类别或其他任何句子标签。
下面链接有一个例子,是用第四种数据格式训练一个SentenceTransformer模型,接着用第二种数据格式微调模型。详见notebook
SentenceTransformers模型可以由人工标注(格式1、格式3)的数据训练,或者是根据句子所属关系自动提取的标签。但很难找到格式4的三元数据,尽管它不需要标签,除非通过MegaBatchMarginLoss的特殊处理。
以上的数据格式在HuggingFace社区都有开源数据集。在下载数据集前,还可以预览它们的格式。以下是一些例子:
- SNLI,与NLI任务相似,每条数据有一个标签表示一对句子的相似程度,例如0表示矛盾、2表示蕴含。
- Sentence Compression dataset的每条数据由正例对组成;COCO Captions和Flickr30k Captions在每条数据中有超过2个正例的句子,可以将它进一步组成多种组合方式的正例对。
- TREC dataset的每条数据包含一个整数标签,它表示句子所属的类别。Yahoo Answers Topics dataset的每条数据包含三个句子和一个主题标签,每条数据可以拆成三个句子。
- Quora Triplets dataset的每条数据有基准句子、正例句子、负例句子,没有标签。
下一步是转换数据集格式至SentenceTransformers模型识别的格式。因为模型是不能直接识别原始的字符串列表,所以每个例子需要转换为sentence_transformers.InputExample类,然后在torch.utils.data.DataLoader类中做batch和shuffle。
首先安装Hugging Face Datasets
pip install datasets加载数据集
from datasets import load_dataset
dataset_id = "embedding-data/QQP_triplets"
dataset = load_dataset(dataset_id)这个例子是使用第四种不含标注的数据格式,在dataset库中:
输入
print(f"- The {dataset_id} dataset has {dataset['train'].num_rows} examples.") print(f"- Each example is a {type(dataset['train'][0])} with a {type(dataset['train'][0]['set'])} as value.") print(f"- Examples look like this: {dataset['train'][0]}")输出
- The embedding-data/QQP_triplets dataset has 101762 examples. - Each example is a <class 'dict'> with a <class 'dict'> as value. - Examples look like this: {'set': {'query': 'Why in India do we not have one on one political debate as in USA?', 'pos': ['Why can't we have a public debate between politicians in India like the one in US?'], 'neg': ['Can people on Quora stop India Pakistan debate? We are sick and tired seeing this everyday in bulk?'...]
可以看到这个数据集的一条数据会包含单句的基准、一组正例句子、一组负例句子。
转换为InputExample类型,
- 为了方便只保留一条正例和一条负例
- 如果为了提升效果,可以增加数据条数
from sentence_transformers import InputExample
train_examples = []
train_data = dataset['train']['set']
# For agility we only 1/2 of our available data
n_examples = dataset['train'].num_rows // 2
for i in range(n_examples):
example = train_data[i]
train_examples.append(InputExample(texts=[example['query'], example['pos'][0], example['neg'][0]]))
转换为Dataloader
from torch.utils.data import DataLoader
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=16)下一步就是选择合适的损失函数
训练SentenceTransformers模型的损失函数
还记得刚才提到的四种数据格式吗,每一种都有适合的损失函数。
第一种格式会包含句子对和表示他们相似程度的标签。损失函数的优化方向需要考虑:1. 相似的句子对的编码向量在向量空间尽可能距离近;2. 不相似的句子对的编码向量在向量空间尽可能距离远。如果标签是正整数,损失函数使用ContrastiveLoss或SoftmaxLoss,如果标签是小数,使用损失函数CosineSimilarityLoss。
如果只有相似句子对没有标签,可以使用MultipleNegativesRankingLoss。如果想要转换成(基准、正例、负例)的形式,可以使用
MegaBatchMarginLoss当数据集是
[基准、正例、负例]格式,每一个都有整数标签时,损失函数的优化方向需要考虑,基准和正例的向量空间距离要比基准和负例的向量空间距离更近。这时可以使用BatchHardTripletLoss,它需要数据被标注为代表类别的整数,相同类别的句子更接近,因此,基准和正例需要属于同一个标签,同时负例是其他标签。同时,也可以选择 BatchAllTripletLoss, BatchHardSoftMarginTripletLoss, 或BatchSemiHardTripletLoss。他们的区别请看SentenceTransformers官方文档。如果只有三元组,没有标签,可以使用TripletLoss。它最小化基准句与正例句的距离同时最大化基准句与负例句的距离。
下图列举了不同的数据集格式与社区上数据集例子、适合的损失函数。
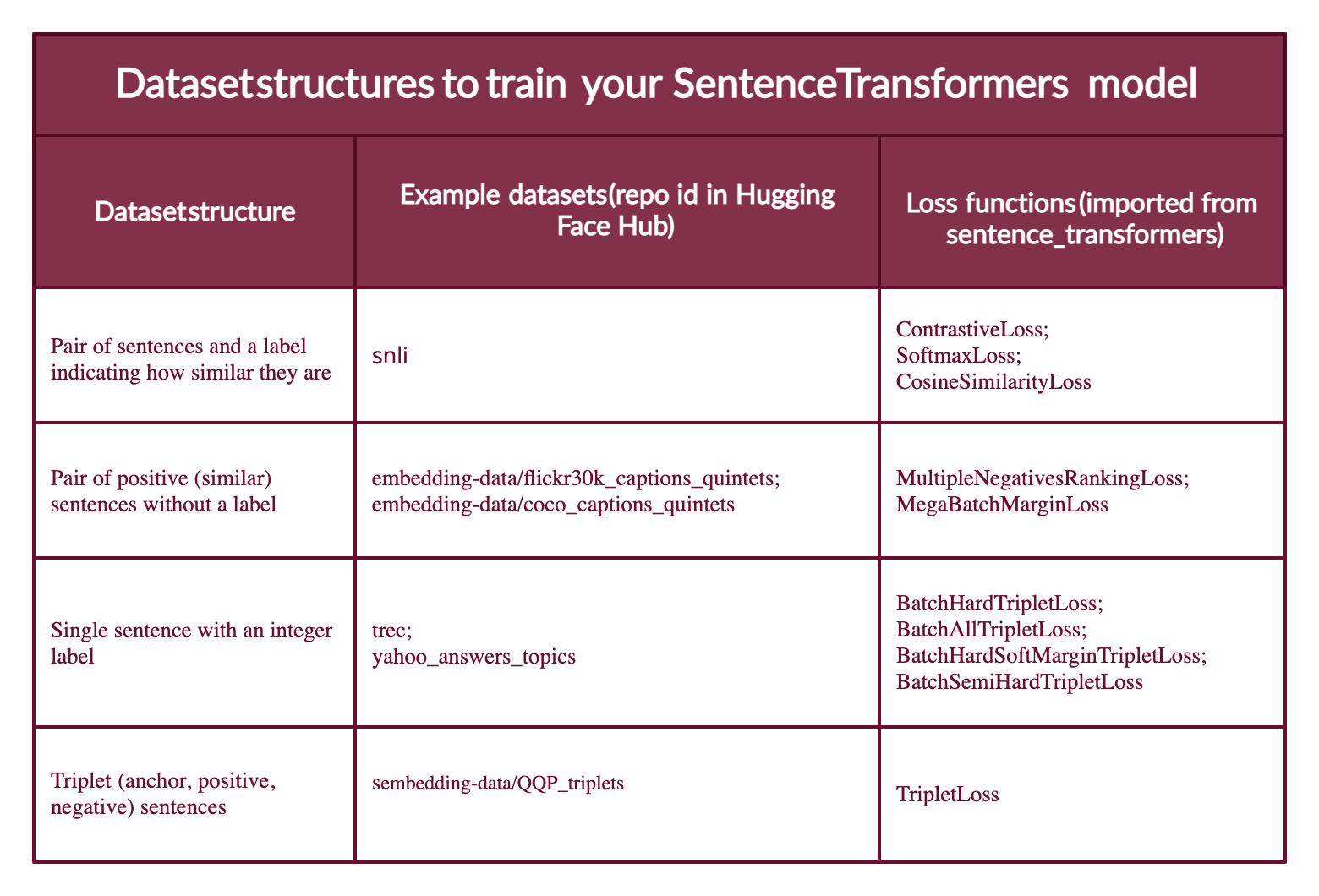
最难的部分是选择一个合适的损失函数。在代码中为以下两行
from sentence_transformers import losses
train_loss = losses.TripletLoss(model=model)一旦数据格式与合适的损失函数确定了,训练SentenceTransformers模型就简单了。
如何训练一个SentenceTransformers模型
SentenceTransformers 的设计就是为了让微调句子/文本编码变的更简单。这里提供了很多功能,可以直接用来在特殊的任务上做编码模型的微调训练。- Sentence Transformers 文档。
训练和微调模型的代码就像下文一样简单
model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=10)如果需要在已有SentenceTransformers模型上做微调,只需要在模型上调用fit函数即可。如果是一个新的SentenceTransformers模型,只需要按照上一节定义它即可。
当你有一个新的改善过的SentenceTransformers模型!你想在HuggingFace社区分享吗?
首先,登录HuggingFace社区,从Account Setting获得token密码。然后两步登录:
- 在终端输入
huggingface-cli login,然后输入token密码 - 如果在
notebook中,输入from huggingface_hub import notebook_login notebook_login()
接下来,可以在已训练的模型上通过save_to_hub方法分享模型。模型默认会上传到账号中。然而,也可以通过传参数至save_to_hub上传至组织。自动生成模型卡片、推断调试器、代码例子片段,和其他的一些细节。也可以把训练模型用的数据集上传至社区模型卡片中。
model.save_to_hub(
"distilroberta-base-sentence-transformer",
organization= # Add your username
train_datasets=["embedding-data/QQP_triplets"],
)在Notebook中,我通过embedding-data/sentence-compression数据集和MultipleNegativesRankingLoss损失函数微调模型。
SentenceTransformers的适用范围
在语义搜索领域,SentenceTransformers比Transformers更好用。然而,如果是做分类任务,Transformers library会是更好的选择。
其他资源
- Getting Started With Embeddings.
- Understanding Semantic Search.
- Start your first Sentence Transformers model.
- Generate playlists using Sentence Transformers.
- Hugging Face + Sentence Transformers docs.
感谢阅读,让我们开始做语义编码吧。